建立于2025-10-27
Stanford CS231n: CNN for Visual Recognition - CS自学指南
课程资源
- 课程网站:http://cs231n.stanford.edu/
- 课程视频:https://www.bilibili.com/video/BV1nJ411z7fe
- 课程教材:无
- 课程作业:http://cs231n.stanford.edu/schedule.html,3个编程作业
CS231n/EECS598学习笔记 - Cyrus’ Blog
EECS 498-007 / 598-005: Deep Learning for Computer Vision | Website for UMich EECS course 也可以
(39) Stanford CS231N Deep Learning for Computer Vision I 2025 - YouTube
Stanford University CS231n: Deep Learning for Computer Vision schedule
1JI0O/cs231n_assignments 我的作业仓库
CS231n 2025——作业参考与学习笔记导航页-CSDN博客
参见CS231n作业
快进来和我一起入门优化吧(课程安利分享) - 人生经验 / 学习进阶 - 水源社区
Lecture 1: Introduction
1.0 课程介绍-计算机视觉概述
2025-10-27 21点17分 看完了01
主要是介绍这节课是干嘛的
1.1 课程介绍-历史背景
关于新旧课程衔接
- 考虑视频观看2017版
- slides使用最新slides
notes
- 生物的视觉演化
- 计算机视觉的历史
- 1966 mit summer vision project → popular area
- David’s VIsion
- imput - edge - 2.5d - 3d
- generalized cylinder & 点和线
- normalized cut
- face detection
- SIFT feature
- 空间金字塔匹配
- human recognition
- object recognion
- datasets & benchmark
- can we recognise all objects
- imageNet
- 2012 - CNN
1.2 课程介绍 - 课程后勤
notes
- object detection
- draw boxes
- image caption
- 1998 LeCun CNN
- understand a pic in a 丰富、全面 way
人员安排
- 李飞飞主导
- 讲师们是李手下的博士生
- 还有一堆TA
philosophy
- 透彻&详细理解
- 动手做
- 这门课是sota,特别新
- fun
thoughts
- 还是用中文记笔记吧,有些术语倒是可以用英文
- 看完一节网课,应该看看对应的最新ppt
- 2025-10-28 20点19分
Lecture2
2.0 图像分类-数据驱动方法
Asignment1 numpy教程
data-driven appproach
- 收集数据和标签
- 机器学习,训练个分类器
- 用非训练数据评估
- 两个函数
- 一个训练,接受数据输出模型
- 一个预测,接受模型输出预测
- cifar-10数据集 - 用于作业
- 寻找最近邻居
- Nearest Neighbor Classfier
- K-Nearest Neighbors
- 多数投票
- k大则决策边界平滑
- 训练速度很快,但是预测速度很慢(要求性能多)
20点37分 看完了
thoughts
- 既然我没有谷歌云的优惠券,那我就在本地完成作业
2.1 K最邻近算法
相对于L1距离(曼哈顿距离),更常见距离算法:L2距离(欧氏距离)
改变(旋转)坐标轴:对L1有影响,对L2没有
指定距离函数,可以测量很多东西之间的“距离”,比方说文字。KNN可以适用于很多东西的分类
vision.stanford.edu/teaching/cs231n-demos/knn/
k不是越大越好,太大了可能会欠拟合,当然太小了会过拟合
如何根据问题和数据来选择超参数:不一定能从数据中学习得到,需要自己手动指定
多尝试超参数组合,看看哪种最好
糟糕想法:选择精度最高的超参数组合
- 太完美了
- 于是过拟合了
- 关键:不是在训练数据上完美,而是能适用于训练数据以外的数据
同样很糟糕的想法:选择在测试集上表现最好的组合
- 导致对test数据”过拟合“4
- 可能只对test数据表现不错
- 泛化能力不行
- 这个不是因为训练时过拟合,而是因为选择了最适合test的数据
- 数据分成train和test
不错的:数据分成3组
- train
- 验证 validation
- test
- 用验证数据判断超参数行不行,最后才用test看准确率
也不错的:k折交叉验证
- 适用于小数据,不常用
- 数据分成几折,每次选择不同折作为验证数据,循环很多组
- 但是这样太慢了,要训练很多次
测试集train和验证集validation
- 模型不知道验证集的标签
- 这个就是用来检测当前超参数的准确性的
数据集划分是随机的(全面的),就可以避免模型学习不全面
得到:超参数与准确率的关系图,选择出在验证数据上表现最好的
knn的问题
- 在测试(验证)时很慢
- 像素距离不适合表达图像之间的差异/不能包含什么图像信息
- 很不同的图片可能有相同的L2距离
- 相同的图片,通过特定处理,可以和不同的其他图片L2距离类似
- 维度灾难
- 希望训练数据密集分布在空间中
- 但是这就需要指数增长的训练数据,随着维度增加
09点16分 看完了
2.2 线性分类1
线性分类器,是巨型模型组成部分之一,如同搭积木
数据x,参数/权重W
编写正确的F的函数形式
这里, :矩阵乘一个列向量得到一个列向量,加上偏置b,得到最终结果,仍然是个列向量
线性分类器只能学习每个类别的一个模板
- 每个W和b对应一个分类器
- 分别计算出最终结果,比对
- 可能得分最高的分类器对应的类别就是测试数据属于的类别
多分类问题:线性分类器不好解决
16点06分 看完了
thoughts
- 有点奇怪,2025的slides上softmax是属于lecture2的,但是貌似2017年的这个不是,也可能是b站课程视频分类比较独特,分的比较细
Lecture3
损失函数
损失函数:每个单独数据损失值(误差)的平均值,损失越低,效果越好
svm损失函数
如果预测对了,比方说 很小,很大,那么损失就是0 如果预测错了,损失就是正的 只关心正确的分数是否比不正确的分数大1 为什么选择了1,因为这就是个可以随便选的值,无所谓,会在“放缩操作”中被抵消
一开始时,loss函数值应该是差不多 类别数-1(正确的和错误的分数都差不多),可以用于检测程序是否有bug
计算loss的小技巧
margins = np.maximum(0, scores - scores[y] + 1)这一步会对所有类别都算 margin,包括了正确类别自己(这时 margin=1)。- 但正确类别的 margin 没有意义,它不应该被加进损失里,所以单独设成0:
margins[y] = 0
关键的不是找到拟合训练数据集的W,而是通过训练数据集找到一些不错的分类器W,它们在测试数据上效果不错
正则化 regularization
为了解决过拟合,需要引入正则化项
Data loss: Model predictions should match training data 模型预测需与训练数据匹配 对应公式中 部分
Regularization: Model should be “simple”, so it works on test data W应该简约 对应公式中 部分)
当然,简约也要取决于问题规模
常用:
L2正则化:
L1正则化:
L2的鲁棒性更好
各种正则化方法度量复杂性的角度(对复杂度有不同的理解)不同,需要根据实际情况(数据和问题)选择
softmax / cross-entropy(交叉熵) loss
(多项式逻辑回归 multinominal logistic regression)
将会赋予分数一些具体的意义
“Softmax classifier”(softmax分类器)这个名字的由来,其实是因为它是一种用softmax函数作为输出层的多分类模型。
希望正确类别的值(意义:概率)接近于1
交叉熵(Cross Entropy)
- softmax 把输出变成概率,才能让“概率”有意义。
- 交叉熵通过概率来衡量模型“有多自信地猜对了”,并指导模型学习。
总而言之,这个就是Softmax损失函数 指的是某个类别获得的分数,下面除以求和是归一化
指数化,再归一化
0是理论最小损失,理论最大损失是正无穷(指数化后的得分是0,也就是说原始得分是负无穷)
2025-10-30 21点03分 看到了 47:36
总体流程
- 数据集(x,y)
- 打分函数
- loss函数
- 正则化
2025-11-02批注:
简言之,Softmax 关注 “正确类别的概率有多高”,SVM 关注 “正确类别得分是否比所有错误类别得分高一个安全间隔”—— 两者的设计逻辑和应用场景各有侧重。
所以softmax里面 只对正确类别进行计算,但是svm都要比对
2025-11-08 对于一个样本,它在n个类别下有n个得分,对n个得分取exp,然后分别处以sum(exp),得到每个类别的概率,这个样本的loss就是对它所属类别的概率取-log 对于得分处理的技巧:把每个类别的得分都减去所有得分中最大值
优化
很蠢:随机搜索,随机产生W,测试效果
不错:遵循斜率
梯度:偏导数组成的向量,和x形状相同,指向函数值增长最快的方向,负梯度方向就指向下降最快的方向
用数值法算极限算梯度(有限拆分),很慢,达咩。不要用数值梯度,不过这是个好的debug工具,如同对拍。用数值梯度检验解析梯度是否正确
微积分:对损失函数计算,得到梯度表达式。用解析梯度是快的且好的。
梯度下降
通过计算梯度,决策下一步应该怎么走(W的参数们应该怎么变化)
步长(学习率):一个超参数,很重要,需要最先调
SGD 随机梯度下降
N太大了,训练一轮会很慢,需要等待很长时间,W才能更新一次
并非计算整个训练集的误差和梯度值
每次训练中,选取一部分训练样本,成为minibatch,通常为2的幂次,例如32/64/128,用它来估算实际误差总和,以及实际梯度。minibatch数据选取是随机的。
Multiclass SVM optimization demo 动手试试,有助于建立直观理解
- 这些线是每个分类器的“零分数等高线”(zero score level set),也叫“决策边界(decision boundary)”。
- 实际上,类别之间的分界线(也叫决策边界)是在两个类别分数相等的地方:
Image Features 转换特征,例如把xy转化成极坐标。正确的特征转换,有助于解决问题,效果更好 介绍了一些例子,感觉挺有意思的
251030 23点27分 看完了 既然softmax已经讲了,那么CS231n作业的1-2 softmax作业也可以开始做起来了
Lecture 4
介绍神经网络-反向传播 这节课是一位女老师在讲
计算图
用这个图表示每个函数,每个节点表示一个运算 利用反向传播,计算梯度 对于复杂函数梯度计算很有用
我觉得计算图的笔记不如看日本人写的那个动物书
- 向前传播:算出最终的值
- 反向传播:算导数/梯度,是链式法则的递归调用
链式法则
反向传播:从最后开始,往前计算所有的梯度
每个节点只知道和它直接相连的节点,一个节点有输入和输出
把复杂的表达式分解成很多个节点计算的组合,而且不用推导整个表达式,只需要算需要计算的
上游的Loss梯度反向传播输入进来,和节点的本地梯度相乘,得到Loss关于当前节点输入的梯度值,递归重复这一操作
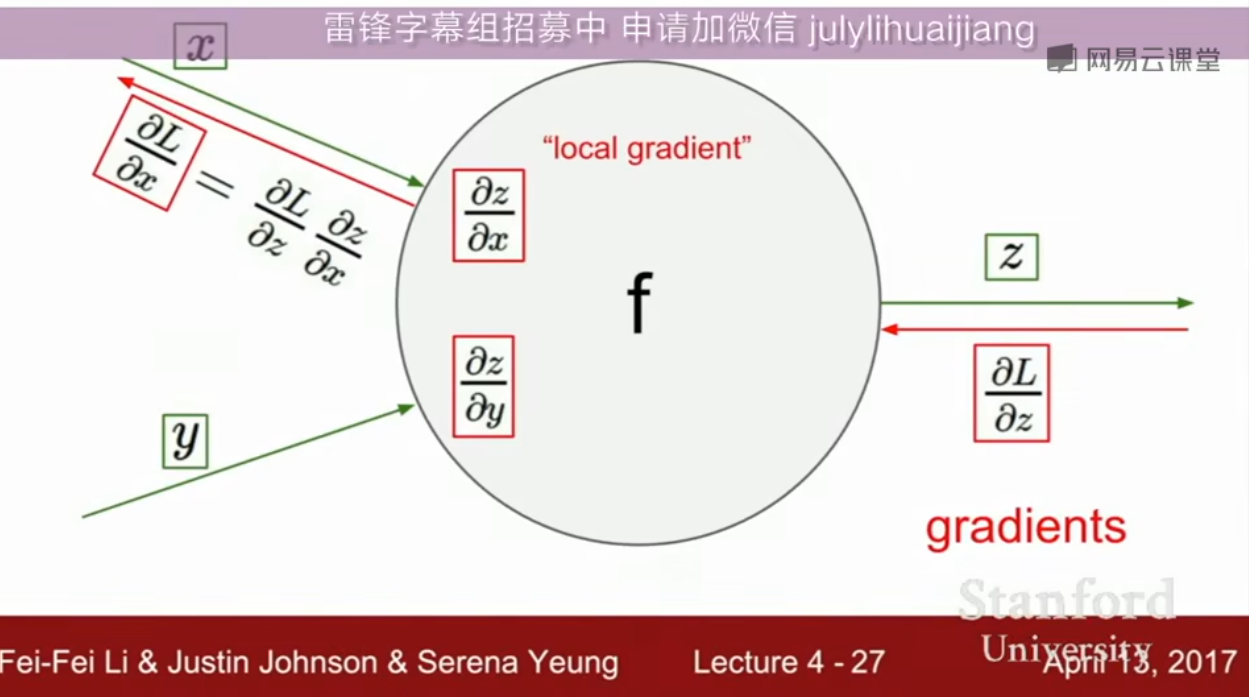
sigmoid
比方说可以把这一坨sigmiod聚合成一个超大节点,只要能写出其本地梯度,然后作为一个一般的节点去处理即可
计算图让梯度计算成为一个可以自动化无脑操作的东西,不用对着那个函数求偏导,只需要按照计算图一步步计算就可以了,老师称算计算图很舒服
啊,b站可以小窗播放,这样使用其他网页上的工具就不用暂停了
max gate?
本地梯度:其中一个是1,另外一个是0;其中一个会获得上游梯度值,另一个就此终结(可以视为对最终loss没有影响,因而梯度为0)
可以视为一个路由器,把反向传播路由到唯一正确的分支上
只有最大值能传播到计算图的后续流程
一个节点连接两个分支
此时其上游梯度是后续两个分支传回来的梯度的和
矩阵操作
Jacobian矩阵,雅可比矩阵
在深度学习中,Jacobian(雅可比)矩阵主要用于描述一个向量输出对向量输入的偏导数关系。它是链式法则在多维情况下的推广
某个变量的梯度应该和这个变量的形状是一样的

注意那个的转置
模块化实现:forward/backward API
比方说,正向传播时缓存一下x和y的值,反向计算时就可以直接用
summary so far
Summary so far…
- neural nets will be very large: impractical to write down gradient formula by hand for all parameters
- backpropagation = recursive application of the chain rule along a computational graph to compute the gradients of all inputs/parameters/intermediates
- implementations maintain a graph structure, where the nodes implement the forward() / backward() API
- forward: compute result of an operation and save any intermediates needed for gradient computation in memory
- backward: apply the chain rule to compute the gradient of the loss function with respect to the inputs
assignment1-2 SVM/Softmax
原来里面涉及到计算图相关知识,正推和反推需要手写,有意思
介绍神经网络
来个线性层,再来个非线性层,再来个线性的
神经网络:很多种函数分层组合起来,线性的和非线性的,合成一个超大非线性函数
我不理解,啊我又理解了,我做的作业是2025版的,这个的2层神经网络合并在作业1,但是2017年的这个中,2层神经网络在作业2,看来难度在逐年加大。 Stanford University CS231n: Deep Learning for Computer Vision 2025 Stanford University CS231n: Convolutional Neural Networks for Visual Recognition 2017 问了问ai,虽然2025年作业没那么强调底层知识,可能部分细节不需要自己手写了,但是它更加线代,包含很多现代的知识
神经网络结构和神经元结构还真的有点像
2025-11-02 10点37分 看完了
Lecture 5
卷积神经网络历史
AlexNet到ConvNets
有一说一,我觉得需要看一看关于transformer的课程,毕竟这个2017的里面没讲,也许3b1b的不错,也许2025 cs231n也不错
卷积 Convolution
可以保全空间结构,不要展开成一个长长的向量
权重是卷积核 filter
卷积核会遍历所有通道,比方说一个图是3通道,这个卷积核也是
32x32x3 image 5x5x3 filter
使用卷积核:
关于这个转置,没什么直观的解释,只是因为我们需要这么做才能算
实际上是2个矩阵在做卷积运算(对应位置相乘再相加),但是这个和把对应区域展开成一个长长的向量再点乘的结果是一样的
一个像素一个像素,或者一次多个像素,滑动卷积核,每次算出一个值,组合成一个新的矩阵,作为结果,关于这个结果的形状
用很多个不同的卷积核,得到不同的结果,提取到不同的特征,这个结果叫激活映射,也就是activation map
前面的卷积层代表粗浅的特征,比方说边缘,中间的复杂一点,比方说纹理,斑点,后面的就更复杂了
步长stride,一般输出大小:
为了不忽略边缘特征(主要是角落),需要进行边缘填充,比方说全部是0。此外,填充还可以确保输出和原图像尺寸相同,如果不填充,每一层会越来越小,久而久之就完蛋了。
填充就是pad,需要注意的是,填充之后算输出大小,不要忘记左右都要填充,N要加pad*2
Convolution Summary

注:kernel,filter这些一般都是指卷积核,是一个东西
- Stanford CS231n FAQ 链接:
“In the context of ConvNets, filter, kernel, and feature detector are synonymous terms that refer to convolutional weights.”
池化 Pooling
让生成的表示,更小,更好控制,让最后有更少的参数;降低采样。
max pooling
max pool with 2x2 filters and stride 2,取2x2方块最大值,作为代表
池化层的处理区域不应该有重叠
直观来看,可以说是对一张大图片做了压缩,提取每个部分的最大特征。用一个数值代表整个区域
最大池化比平均池化用得更多,因为可以更好提取一个卷积核对于一个区域的反应的激烈程度
池化不需要边缘填充,如果最大值在边缘,可以被提取到
Pooling Summary

全连接层 Fully Connected Layer (FC layer)
把最后一层的输出,是个矩阵,把它直接拉平,不需要之前的空间结构了,需要把信息全部聚合在一起
Summary
- ConvNets stack CONV,POOL,FC layers
- Trend towards smaller filters and deeper architectures
- Trend towards getting rid of POOL/FC layers (just CONV)
- Historically architectures looked like
[(CONV-RELU)*N-POOL?]*M-(FC-RELU)*K,SOFTMAX- where N is usually up to ~5, M is large, 0 ⇐ K ⇐ 2.
- But recent advances such as ResNet/GoogLeNet have challenged this paradig
Lecture 6 & 7
训练神经网络
part1
激活函数

sigmoid问题
- 杀死了梯度
- x很小,那么这个节点的梯度是0,会传递到后续节点
- x为0,会得到合理的梯度,可以正常传播
- x很大,节点梯度还是0(处于平滑区域,和很小时一样)
- 输出不是以0为中心的
- 梯度要么是正数要么是负数
- 梯度更新方向很固定
- 总是朝着有限的2个方向移动
- exp()函数运算复杂
ReLU好得很
- 不会饱和(saturate)(在正数区域)
- 算起来快
- 效果更好
- 但是可能会死,毕竟x小于0就输出0,只有大于0的才能存活
为了解决ReLU的die问题:leacky relu
Maxout:在2个函数里面取最大值,不饱和,不消亡
反正一般用ReLu,或者其变体,tanh可以用一下,但是不要用sigmoid
数据处理
step1:预处理
0中心化、归一化数据:消除偏差 没必要归一化太多,主要还是0中心化 (减去平均值) 图像领域,主要就是0中心化

如果不归一化,那么最后得到的loss会对权重变化很敏感,会让学习很困难 (一条分类直线,数据不在中心,直线稍微转动一下,loss会很大)
初始化权重
不能用0作为W的初值,所有的神经元都将做相同的事情,输出相同的数值,得到相同的梯度,总之所有神经元将会一模一样。不能用相同参数初始化
可以:高斯分布:均值0,方差一个较小的数,比方说0.01
这个的可视化统计图理解可以参考那个日本人写的动物书
方差太小会怎么样?(σ 太小)
- 只有离中心很近的数据权重大,其它几乎被忽略 → 变得很“挑剔”,能用的数据变少了。
- 很容易过拟合:本地的噪声和异常值会影响巨大,结果不稳定。
- 数值容易出问题:远处的数据权重接近于0,梯度也容易消失或突然变大,训练难收敛。
- 采样方法(比如粒子滤波)会导致权重极度不均匀,只有很少一部分样本“活着”,效率变低。
很小的数,不断相乘,随后会变成0,然后就全部死了
方差太大会怎么样?(σ 太大)
- 权重 exp(-d²/(2σ²)) ≈ 1,对所有输入都几乎一样,缺乏区分度。
- 经过激活函数(如tanh、sigmoid)之后,输入很大/很小,会让神经元直接饱和到极值(比如 tanh 输出接近 -1 或 1)。
- 梯度全为0(因为饱和区的梯度很小甚至为零),网络无法学习。
一句话总结
- 方差太小 ⇒ 激活为0,梯度为0,模型学不到东西
- 方差太大 ⇒ 激活函数饱和(全是极值),梯度为0,模型也学不到东西
- 都导致梯度消失,网络无法有效训练!
Xavier初始化:
- 它的目标是让每一层的输出方差与输入方差相同,避免信号在网络中传播时不断放大或者缩小(梯度消失/爆炸)。
- 适用于激活函数是 Tanh 或 Sigmoid 的情况。
W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in)是一个例子
He初始化
- 适用于relu
W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in/2)- 毕竟杀死了一半的神经元,所以要除2
2025-11-05 22点30分
Batch Normalization 批量归一化
- 在每一层训练时,把一批数据(mini-batch)的每个特征做标准化处理,即减去均值再除以标准差,让每个特征的分布都类似于标准正态分布(均值为0,方差为1)。
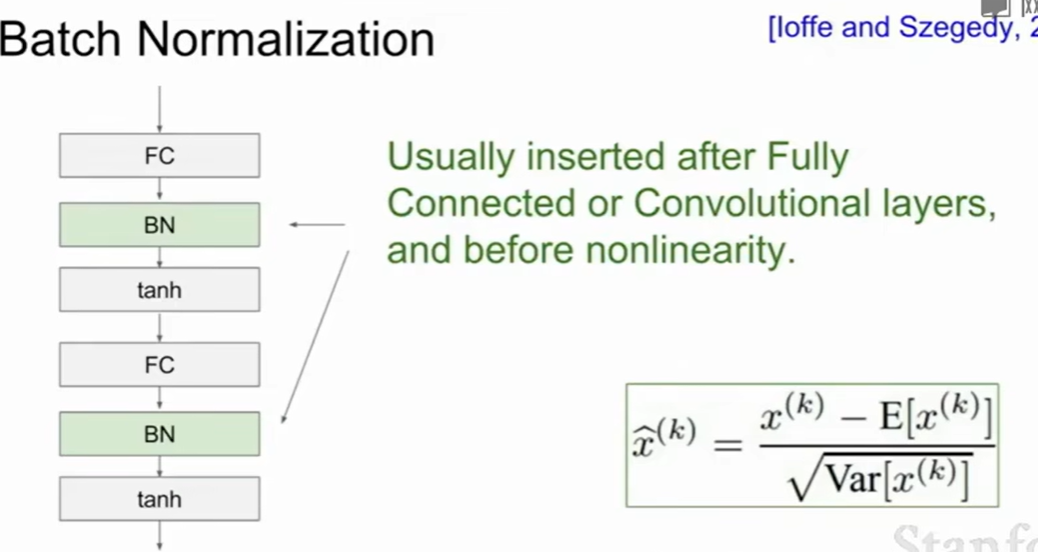
对于每个特征,Batch Normalization 的计算流程如下:
-
计算均值和标准差(对当前 mini-batch):
-
归一化(Standardization):
-
缩放和移位(可学习参数):
其中 和 是可学习参数,可以通过模型训练得到。
第三步的作用:
- 归一化后,每个特征的分布都是均值0、标准差1,这限制了网络的表达能力。
- 所以引入了两个可训练参数 γ(缩放因子)和 β(偏移量)。
- 这样网络可以自己“学习”每个特征应该处于什么尺度和偏移,以获得更强的表达能力。
- 换句话说:虽然归一化标准化了特征,但通过γ和β,网络可以灵活地恢复或者调整每个特征的分布,学到更优结果。
总结 第三步就是让神经网络可以自适应调整归一化后的特征分布,而不是死板地全部都变成“均值0方差1”。
Babysitting the Learning Process
监视训练,并在过程中调整超参数以获得最佳效果
一开始,没训练过权重获得的loss大概知道,加上正则化,loss会变大 先从小数据集开始试试,这时要关闭正则化,看能否把loss降到0,完全过拟合
调学习率
- loss不怎么变小:lr太小了
- loss爆炸:lr太大了
- 一般在1e-3和1e-5之间
超参数优化
cross-validation strategy 交叉验证:训练集训练,验证集验证
- stage 1: 几个epoch(完整跑一遍数据集),大概了解最佳参数所处区间
- stage 2: 多跑会,进一步,更精确
random search vs. grid search random可以包含更多可能性
可以优化的
- 网络结构
- lr,正则化以及它们包含的一切
monitor and visualize loss curve
记录每次参数(权重)更新的幅度和原始参数的大小比例,用来粗略判断学习率(learning rate)、初始化等是不是合适。
- 如果更新比参数本身大得多,可能说明学习率太高,容易训练不稳定甚至爆炸。
- 如果更新非常小,远小于参数本身,可能说明学习率太低、或者梯度消失,训练太慢没进展。
- 一般希望比值在 0.001 左右(不是严格必须的)——这样每步优化都能有效调整参数,又不会动得太猛。
相较于2025课程,lecture6没有介绍具体例子 CNN Architectures (VGG, ResNets) 此外,也没有讲解Data augmentation (cropping, jitter)
Data augmentation(数据增强)是在训练神经网络时,用人工方法“扩充”你的训练数据,目的是让模型更鲁棒、泛化能力更强。
在图像任务里常见的数据增强方法有很多,比如**cropping(裁剪)和jitter(抖动)**就是其中两种。
part2
太好了,回归到Johnson上课了。目前进度是【15】
Optimization
sgd的问题
- 会得到之字形曲线(在前往最小值的路上),在多维上是很大的问题
- 局部最小值&鞍点,sgd会会卡在中间,那个地方梯度是0,或者很小
sgd
while True:
dx = compute_gradient(x)
x += learning_rate * dxsgd+momentum 带动量的sgd
vx = 0
while True:
dx = compute_gradient(x)
vx = rho * vx + dx
x += learning_rate * vx:摩擦系数,比方说0.9, 0.99 : 就是lr
在速度的方向上前进,而不是梯度的方向
由于有了速度,可以越过局部最小点和鞍点
nesterov momentum
(原来ob-latex语法里面,输入del,就会自动生成$\nabla$,)
AdaGrad
grad_squared = 0
while True:
dx = compute_gradient(x)
grad_squared += dx * dx #看这里
x -= learning_rate * dx / (np.sqrt(grad_squared) + 1e-7)
# + 1e-7 主要是为了防止除以0Added element-wise scaling of the gradient based on the historical sum of squares in each dimension
这个会导致lr越来越小,在凸函数情况下,越靠近极值点,越缓慢,就不错
优化:RMSProp
Adam
有点像上述两种优化方法的结合
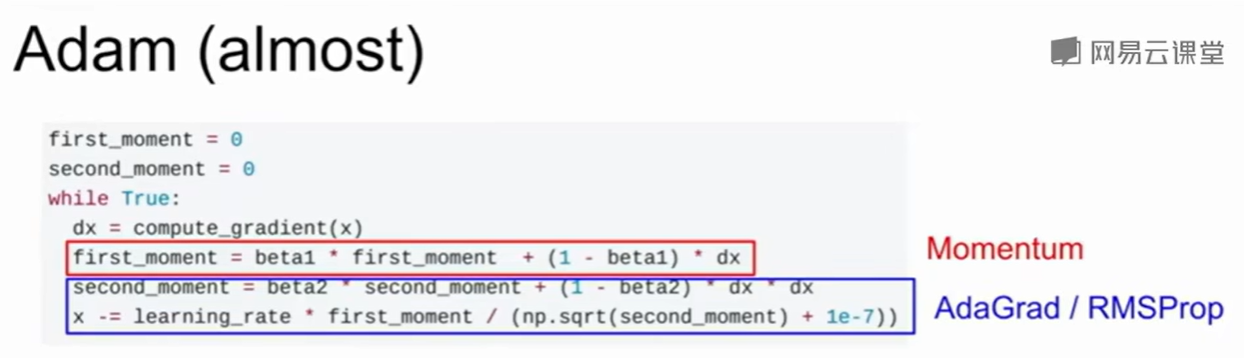
这个基本上是个默认的优化算法,效果和普适性都很好。它是首选!
Adam with beta1 = 0.9, beta2 = 0.999, and learning_rate = 1e-3 or 5e-4 is a great starting point for many models!
步长衰减
指数衰减(exponential decay)
1/t 衰减(1/t decay)
先不用衰减,看看loss曲线,确定哪个地方开始衰减比较合适
一阶逼近 first-order optimization 二阶逼近
newton parameter update 这个时候不需要学习率,直接走到最小值即可 但是这个对于深度学习不友好,这个是O(N^2)的 相似的:L-BFGS 但是效果不好
model ensembles 集成学习
训练很多个模型,取平均,能稳定提升几个百分点,缓解一点过拟合
2025-11-06 22点19分
Regularization 正则化
正则化

Dropout
每次正向传播,都随机把几个神经元置零(将神经元的输出结果置为零)。概率是个超参数,一般是0.5
每次dropout,都是一个不同的子网
训练的时候dropout即可 预测的时候,不要随机丢弃神经元,而是将每个神经元的输出乘以概率 p(保留概率)。
- 或者在训练时对被保留的神经元的激活除以 p,预测时则不做任何改变(这两种方案本质等价,叫作“inverted dropout”)。
- 这样把一个运算在训练时就完成了,更高效
dropout后,训练时间更长,因为每次只是更新一个子网,网络的一部分
batch normalization
参见上面笔记,比较常用,如果效果不够,那么就采取其他方法
data augmentation
数据转换 随机的水平翻转(镜像),随机裁剪图片,色彩抖动(color jitter)
transfer learning 迁移学习
不需要很大的数据集,也能训练cnn。对于小数据集很友好
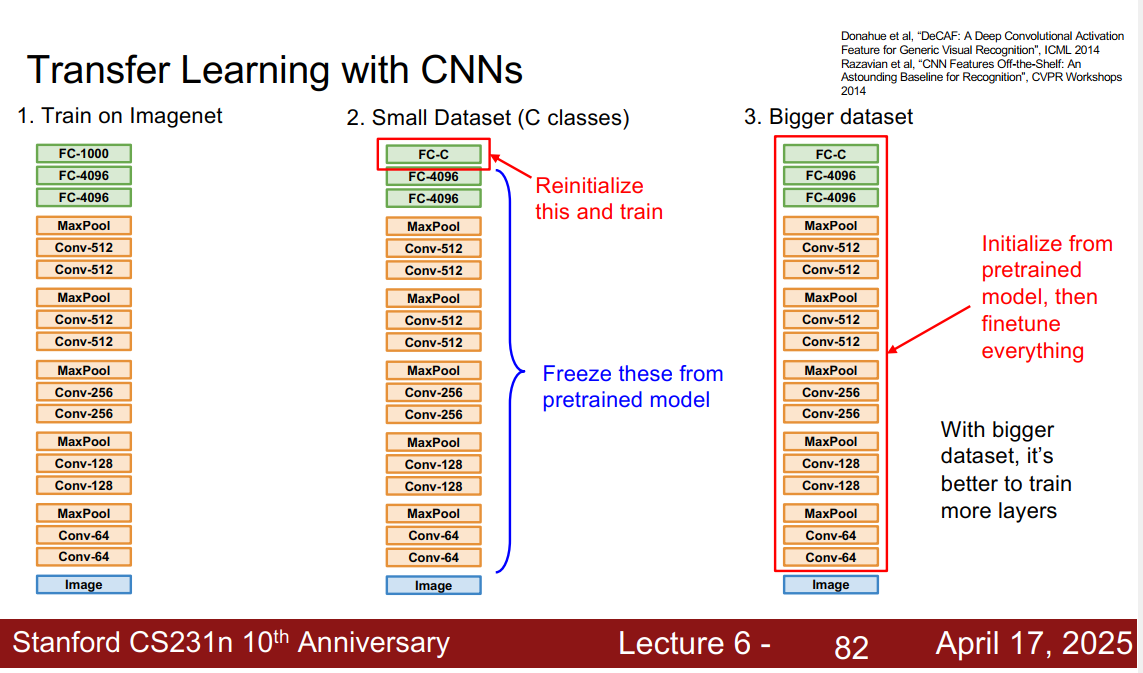
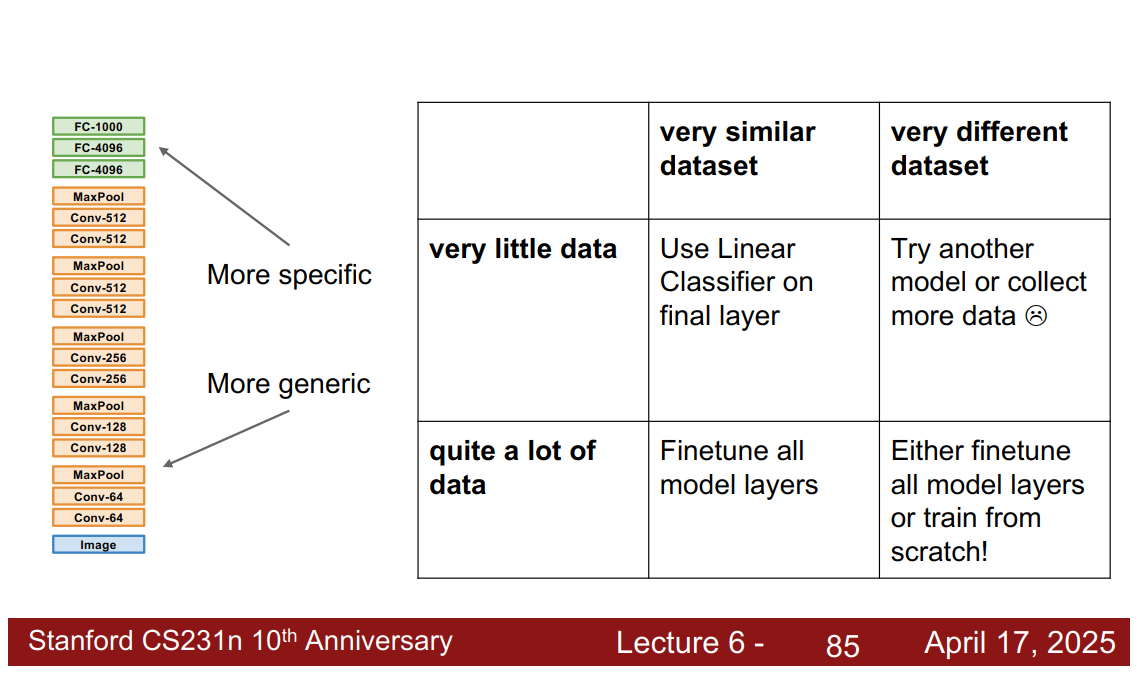
先用imagenet训练,然后微调
22点47分 完成lecture6 下一节是【18】,但是见鬼了,怎么就直接到lecture8了,直接从6到8,很诡异。而且貌似从这里开始,2025版开始和2017版有很大区别,考虑研究一下这些区别,去问一下李哲要如何解决
Syllabus | CS 231N
Lecture 7 Training Neural Networks, part II
Update rules, ensembles, data augmentation, transfer learning
原来是这样,只是ppt里面还是标注的lecture6
lecture 8
深度学习软件(框架?)
有个好消息,tensorflow可以不用看,这是好的
gpu并行计算很好,因为有很多核,所以做矩阵运算很快
哇,Justin觉得pytorch更好用,这是他研究时主要用到的框架。看来他的目光很不错。
深度学习框架
- 方便构建大型计算图
- 容易自动计算梯度
- 可以在gpu上高效运行
问题:在cpu和gpu之间传输数据
51:32才开始进入pytorch
pytorch 三层抽象
- Tensor: Imperative ndarray but runs on GPU
- Variable: Node in a computational graph; stores data and gradient
- Module: A neural network layer; may store state or learnable weights
pytorch tensor and variable have the same api!
Static vs Dynamic pytorch每次向前传播,都构建了新的计算图 (tensorflow是静态计算图,每次需要预先声明好;但是pytorch是动态的,动态计算图) 如果是静态的,框架可能可以对这个静态图做一些优化,同时图作为数据结构可以抽离出来,不必要依赖于原先代码 动态,简洁好写好看,图可以根据情况动态修改,还可以循环
- recurrent network,循环网络
- recursive network
- modular network
- 总而言之,动态图可能性是无限的,可以用它做很多开创性的工作
pytorch : nn,封装好了很多很高级的东西
pytorch : dataloader 很不错的工具
预训练的模型
visdom 可视化一些东西
在2025年caffe框架已经完蛋了,甚至在2017年就已经可以看出来这个东西要完蛋了,怎么会这么复杂,看来确实是学术界做出来的东西,甚至文档都不全,简直是一坨屎
Justin thinks pytorch is best for research
2025-11-08 22点44分 看完了
Lecture 9
怎么是那个女老师讲。这节课是cnn架构,各种例子。这个在b站2017课程中是【19】
AlexNet
一个RGB输入图片,一个卷积核等于有3个独立的平面,每个平面和输入的3个通道做乘加操作,最后再把3个平面累加成一个输出像素。
- 单个卷积核(Filter):
shape = (卷积核高度, 卷积核宽度, 输入通道数)
例如:3×3 卷积核,输入是RGB(三通道),则卷积核 shape 为 (3, 3, 3)。 - 卷积层权重矩阵:
shape = (输出通道数, 输入通道数, 卷积核高度, 卷积核宽度)(PyTorch 常用)
或 shape = (卷积核高度, 卷积核宽度, 输入通道数, 输出通道数)(TensorFlow 常用)
例如:输入图片 (H, W, 3),卷积核大小 (3, 3),输出通道 64,
PyTorch格式下,卷积核参数 shape = (64, 3, 3, 3)
池化层没有参数
AlexNet的“分成两层”感觉,其实源自“分组卷积(group=2)”的用法。
具体是:
- 输入的3个通道(RGB)和输出的96个通道,被分成2组。
- 每组分别处理一半的输入/输出通道,即每组输入1.5个通道,但实际操作重排列。
- 最终,每组输出48个特征图,加起来为96。
- 这样做的原因:在当时显卡显存太小,不能同时处理全部通道,只好分2组各自并行计算。
VGGNet
本质是alexnet的加深和优化
层加深了很多,卷积核很小 3x3cov 2x2max pooling
用小的卷积核:感知视野和大的相同,但是更深,同时参数更少
GoogleNet
更深,可以高效运算
inception模块
2025-11-10 看到了 29:25
关于inception模块
- 局部拓扑,一个网络
- 对上一层的输入做并行的filter操作,然后把每一个核的一个输出层并在一起成为一个tensor
- 通过不同卷积核处理后的操作,尺寸相同,但是深度加深了
- 计算很复杂,需要大量运算
- 1x1“瓶颈层”
- 比方说输入的深度是256,一共有64个1x1卷积核,它们构成了瓶颈层,可以减少深度
- 在进一步卷积层计算之前,比方说在3x3和5x5之前
- 目的是降低输入的深度
- 为了减轻昂贵的计算力
分类输出有3个地方,2个辅助,根据中间层结果分类,一个最终的输出,也就是末端
22层
ResNet 残差网络
152层,深度的革命
残差层
一般而言,层增加时,如果只是单纯加深,表现反而不能表现得更好,无论是训练还是测试,这个还不是过拟合造成的。
这个问题其实是优化问题,更深的更难优化。照理来说更深的模型至少可以和更浅的表现一样好,比方说前面全是较浅模型,后面全都是恒等映射
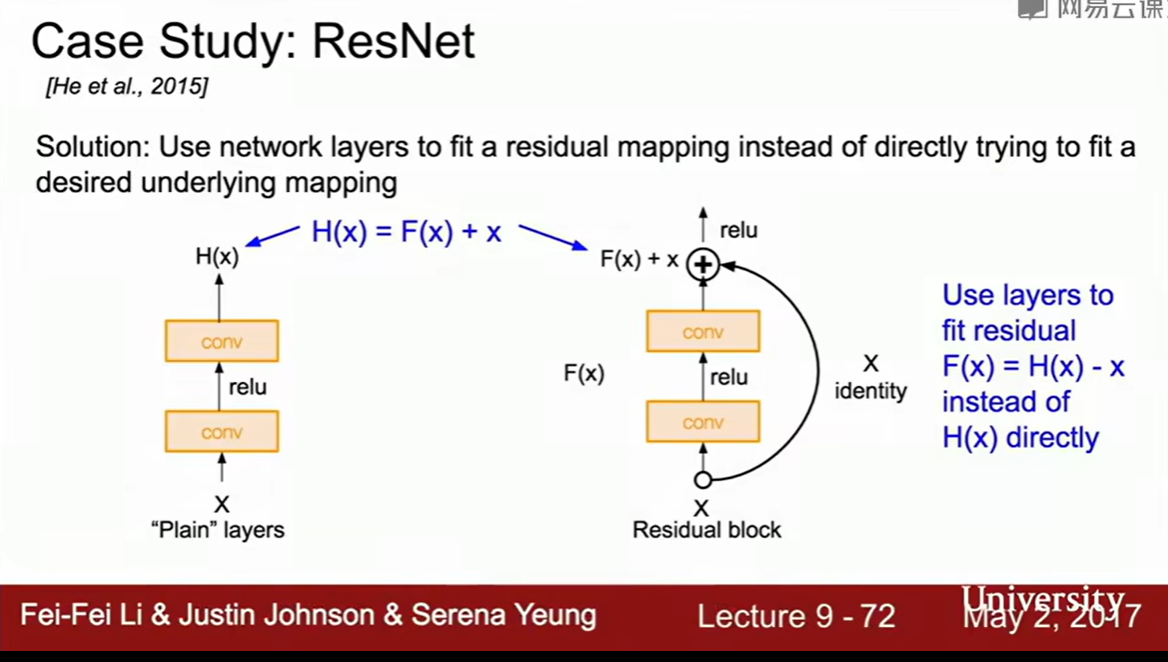 学习残差比学习直接映射简单,这个是他们的假设
学习残差比学习直接映射简单,这个是他们的假设
为了接近恒等映射(和较浅的模型逼近),可以把F(x)压缩到0,然后就是个恒等映射了
把这种残差层堆叠在一起,就是单纯的堆叠
他们也用了瓶颈层,对于较深的网络,类似于googlenet
用了很多额外的优化方法,参见上面的“优化”笔记
其他的架构
NiN:network in network
一些改进ResNet的工作
一些反对resnet残差的工作,比方说fractalnet
让网络高效运行,比方说squeeze net
2025-11-11 23点09分 看完了
lecture 10
rnn,递归神经网络
【【公开课】最新斯坦福李飞飞cs231n计算机视觉课程【附中文字幕】】 https://www.bilibili.com/video/BV1nJ411z7fe/?p=20
回顾上节课讲的: 有了批处理化后,就不需要用各种技巧让模型收敛了 梯度流
“vanilla” neural networks
recurrent neural networks 使用rnn:
- 一对多的模型,输出是可变的序列
- 多对一的模型,输入可变
- 多对多
比方说判断数字,rnn会不断观察这个图象里面不同部分,而不是一次向前传播,马上得出结果
内部隐藏态
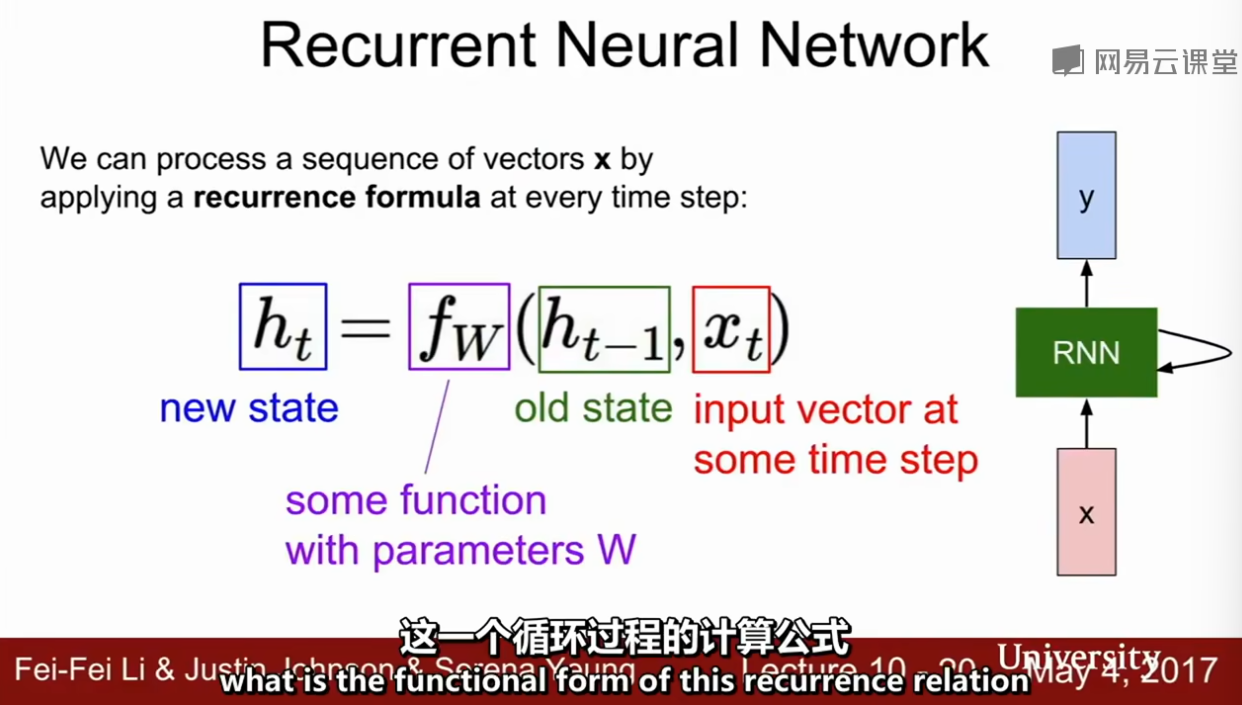
每次用的是相同的函数f和权重W
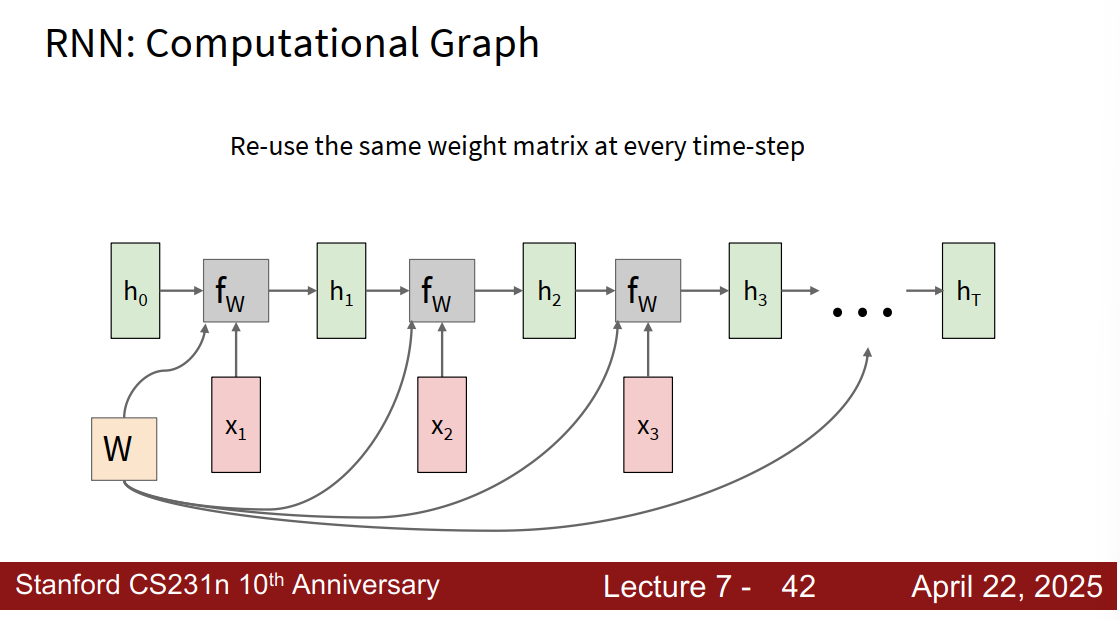
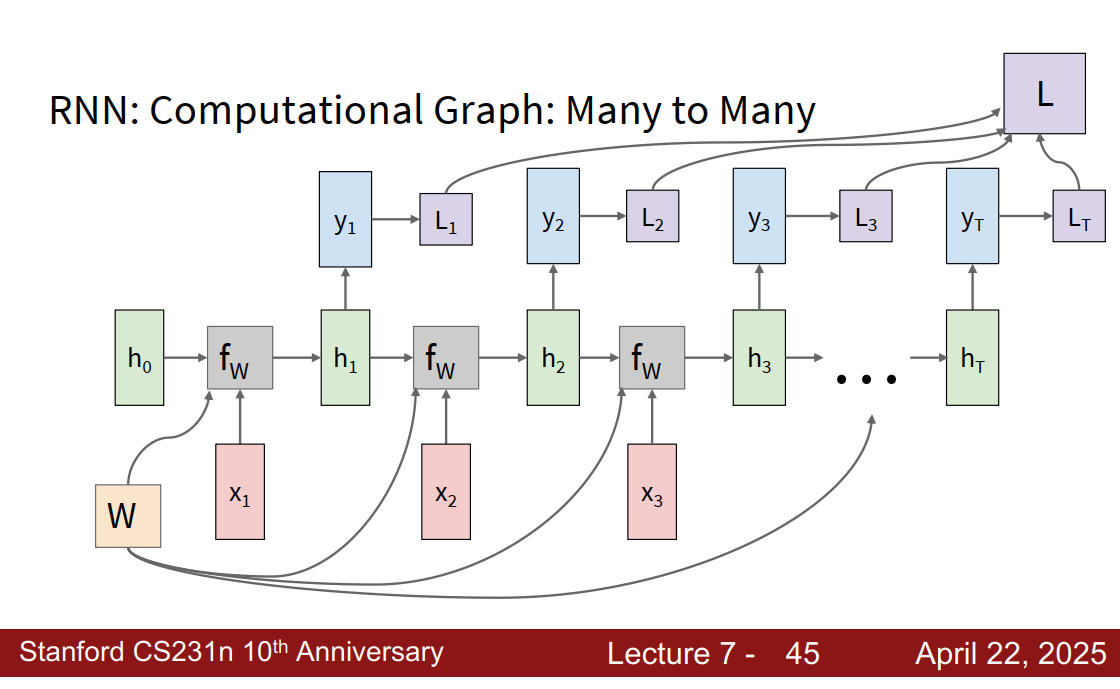
多对单:只在最后有个y 单对多:只有x1输入
编码器和译码器
一般用one-hot变量
Truncated Backpropagation through time
截断式时间反向传播,简称TBPTT,一种近似估计梯度的方法,不用反向传播遍历一个很长的序列
Run forward and backward through chunks of the sequence instead of whole sequence
向前计算若干步,计算子序列的loss
序列的梯度下降,类似于用sgd中取一部分数据计算梯度
by copilot
BPTT(时间反向传播)是训练RNN时使用的反向传播算法。它会把RNN结构在时间轴上展开(比如你有100步序列,就会展开成100层), 然后通过反向传播算法来计算每一层的梯度,从而更新参数。这种方法能捕捉长期依赖,但计算量极大,序列太长时也容易造成梯度消失/爆炸。
TBPTT就是把长序列分成较短的片段(比如长度为k),每次只在一个小片段内展开、反向传播和参数更新。
- 举例:你有一个长度为1000的输入序列,但是只用每20步做一次反向传播。即从t=1到t=20做一遍BPTT,然后t=21到t=40再做一次。每次仅计算k=20步内的梯度,参数也每k步更新一次。
- 这样做的好处是:大幅减少计算量和内存占用,而且能缓解梯度爆炸/消失的问题。
总结:TBPTT就是将长序列训练中的反向传播“截断成小段”,分段训练RNN,既高效又降低长序列难题。
一些例子
rnn学习到了一些类似于语料内部结构的东西,很有意思
虽然只是被训练为预测下一个字符,但是它能弄出来一些能完成特定功能的神经元,有意思
cnn产生特征向量,作为rnn的第一个输入,组合起来用
啊,怎么2017年这个课程就有attention了,此attention是彼attention吗
visual question answering
结合各种模型,把cv和nlp结合起来,cool
一个状态有多个隐藏层
gradient flow
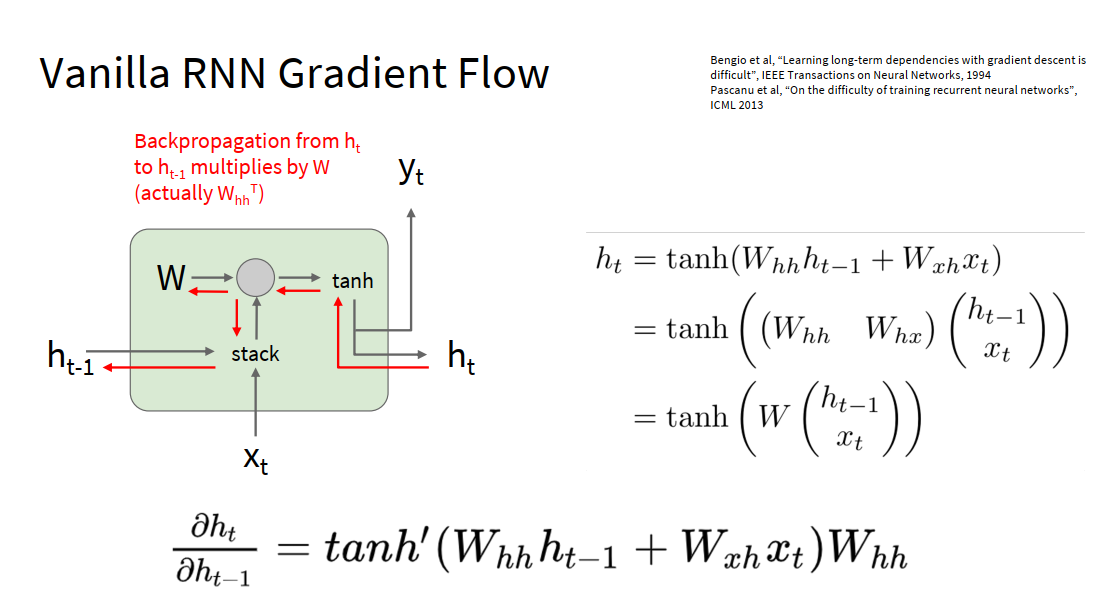
很多个这样的结构连接在一起时,不断地相乘很可能会梯度爆炸或者梯度消失
Largest singular value > 1: Exploding gradients 解决办法: Gradient clipping: Scale gradient if its norm is too big 梯度裁剪
Largest singular value < 1: Vanishing gradients 解决办法: Change RNN architecture
Long Short Term Memory (LSTM)
2025-11-14 23点50分 看到了【22】17:09
更高级的递归形式,缓解梯度消失和爆炸,设计一些更好的结构,获得更好的梯度流动,而不是在输出上下功夫。
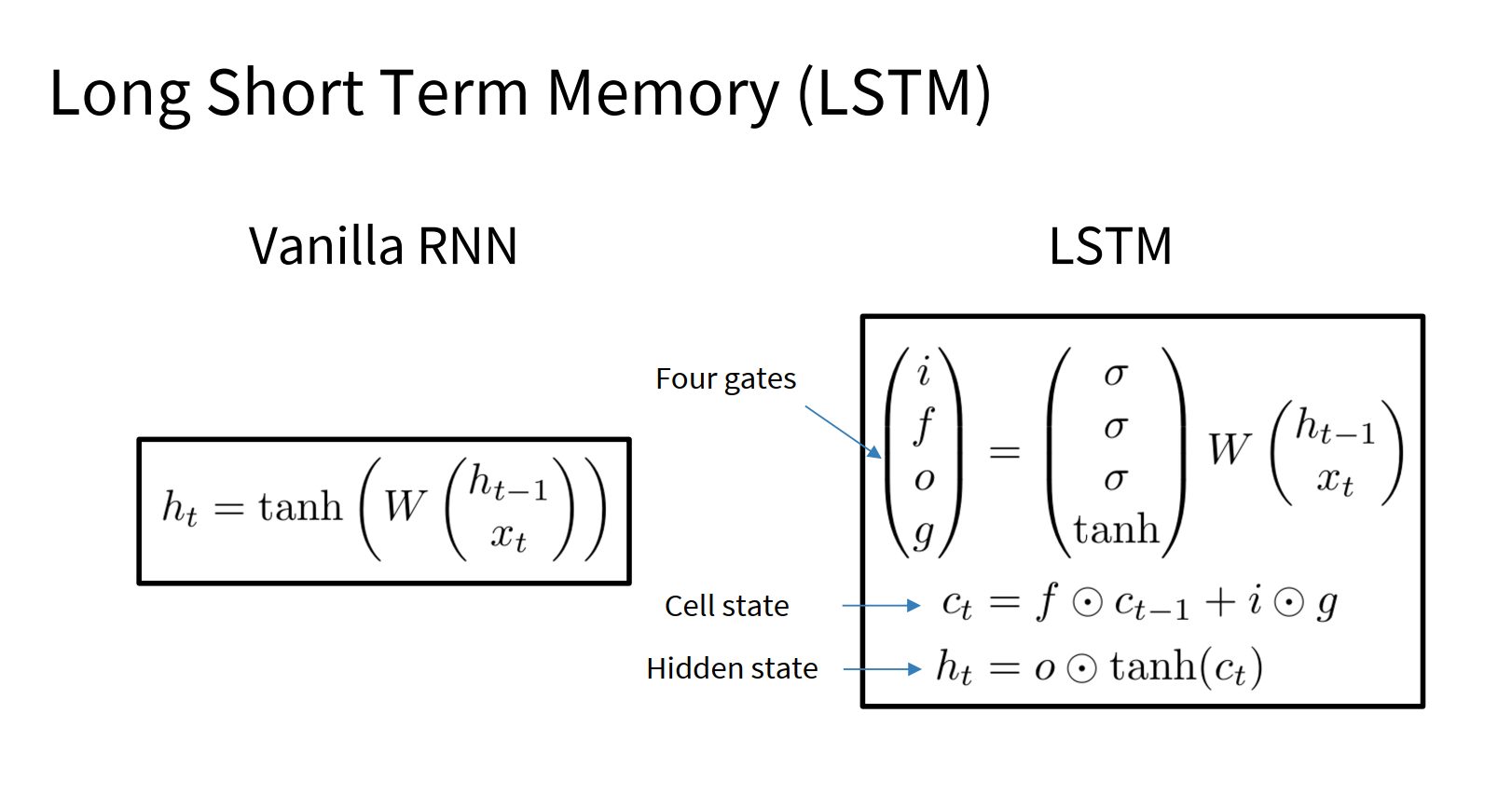
用输入计算4个gate
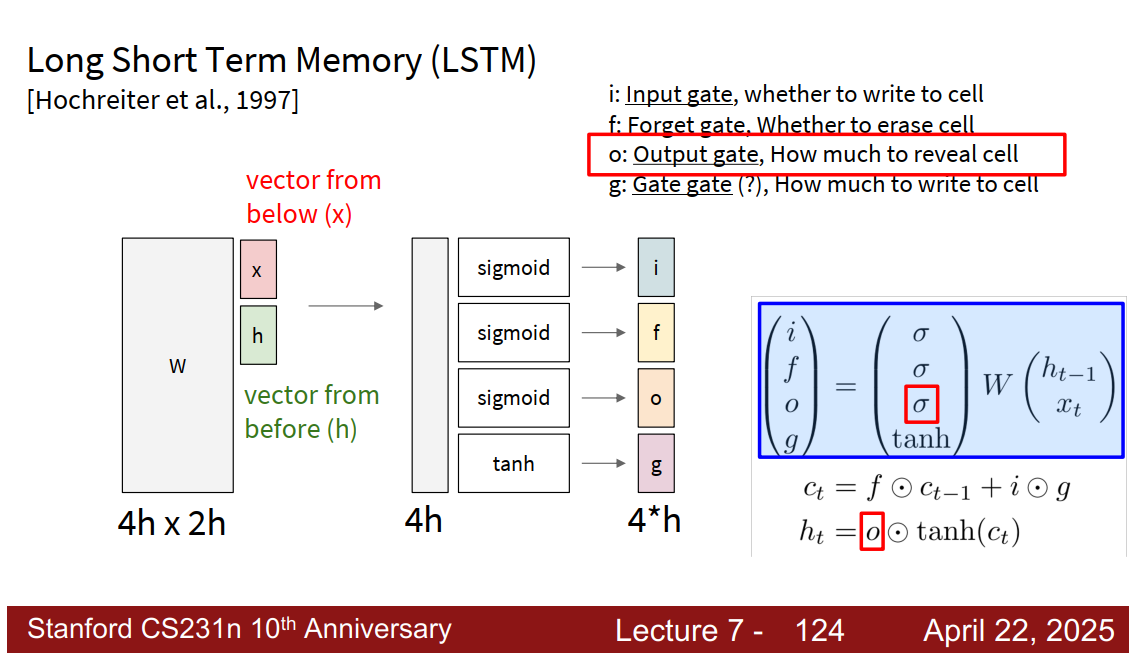
ifo门使用sigmoid,值在01之间,g使用tanh,在-1和1之间
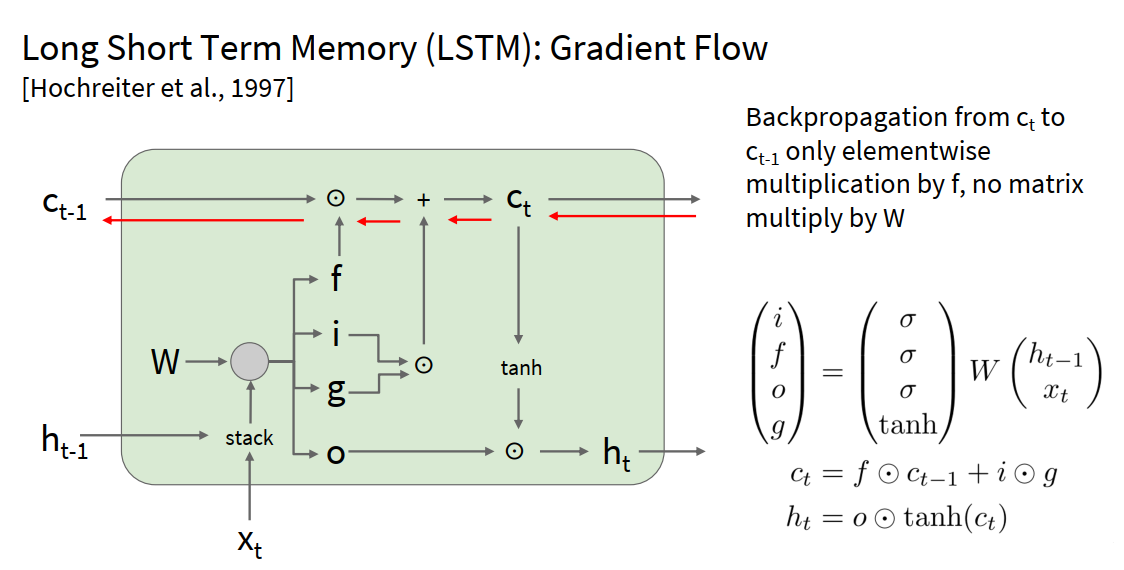
遗忘门在每个时间点都可以发生变化,可以避免梯度爆炸or消失;此外,遗忘门来自sigmoid,所以矩阵元素相乘结果会保证在0到1之间,
Uninterrupted gradient flow!
by copilot
- LSTM中的cell state通过加法累积来自不同时间步的信息。门控结构只通过乘法门控“多少信息流过”,但不会像传统RNN那样所有信息都要在乘法链路中。
- LSTM有一条被称为细胞状态(cell state,记作 )的主线。
- 这条路径大部分情况下直接在每个时间步以加法传递(而不是乘法),只有少数地方会受到门控(gates)的点乘影响。
这个和resnet有点类似,尤其是那个主线
Summary
- RNNs allow a lot of flexibility in architecture design
- Vanilla RNNs are simple but don’t work very well
- More complex variants (e.g. LSTMs, Mamba) can introduce ways to selectively pass information forward
- Backward flow of gradients in RNN can explode or vanish. Exploding is controlled with gradient clipping. Backpropagation through time is often needed.
- Better/simpler architectures are a hot topic of current research, as well as new paradigms for reasoning over sequences
2025-11-15 15点41分 看完了 lecture 10
lecture 11
识别和分割,这个在2025课程里面对应lecture8,Attention and Transformers 不对,课程结构改了
- 2025版
- lecture 7 : rnn
- lecture 8 : Attention and Transformers
- lecture 9 : Detection, Segmentation,Visualization
- 这个貌似是2017课程l11全部和l12一部分
- 2017
- lecture 10 : rnn
- lecture 11 : Detection, Segmentation
- lecture 12 : Visualization 和 理解
我觉得这个看完之后可以去看看2025的transformer,或者在网上找一点网课看看
欸,我发现2025年也有部分课程是justin讲的。看了看b站上课程,感觉他没那么年轻了,唉。 【【公开课·2025春季】李飞飞·斯坦福CS231n计算机视觉课程(全18讲)】 https://www.bilibili.com/video/BV1b1agz5ERC/?p=13&share_source=copy_web&vd_source=278a61d55ec01fcfa1504d3f39f06bbe 但是这个人:Ehsan Adeli,讲得不行,考虑对应课程去找替代品。
图像分类和定位
除了预测分类,也想知道在哪里,又比如说画个框框出来
以alexnet为例,除了用一个全连接层给出分类,用另一个全连接层,给出边界框的参数,坐标和尺寸,所以现在模型给出2个输出,于是也会有2组损失。
比方说可以用于姿势识别
对象识别 object detection
这个和分类和定位不同,这个里面对象个数是不确定的,所以每张照片都可能有不同的输出,所以不能用回归的思想解决这个问题
滑动窗口
窗口滑动,窗口框出来的部分输入模型,模型给出这个窗口的结果,no dog,no cat,no background
问题在于,如何选择crop(裁剪),对象位置和大小都不一样,可能要尝试很多次才可以,而且每次都要通过一个超大的网络,复杂度很高
region proposals : r-cnn
在深度学习不常见,更加常见于传统cv
从图像中找出可能包含对象的区域,候选区域
目标检测,这个很快,目标大概率会在候选区域之中
R-CNN 这篇论文就是关于这个方法的
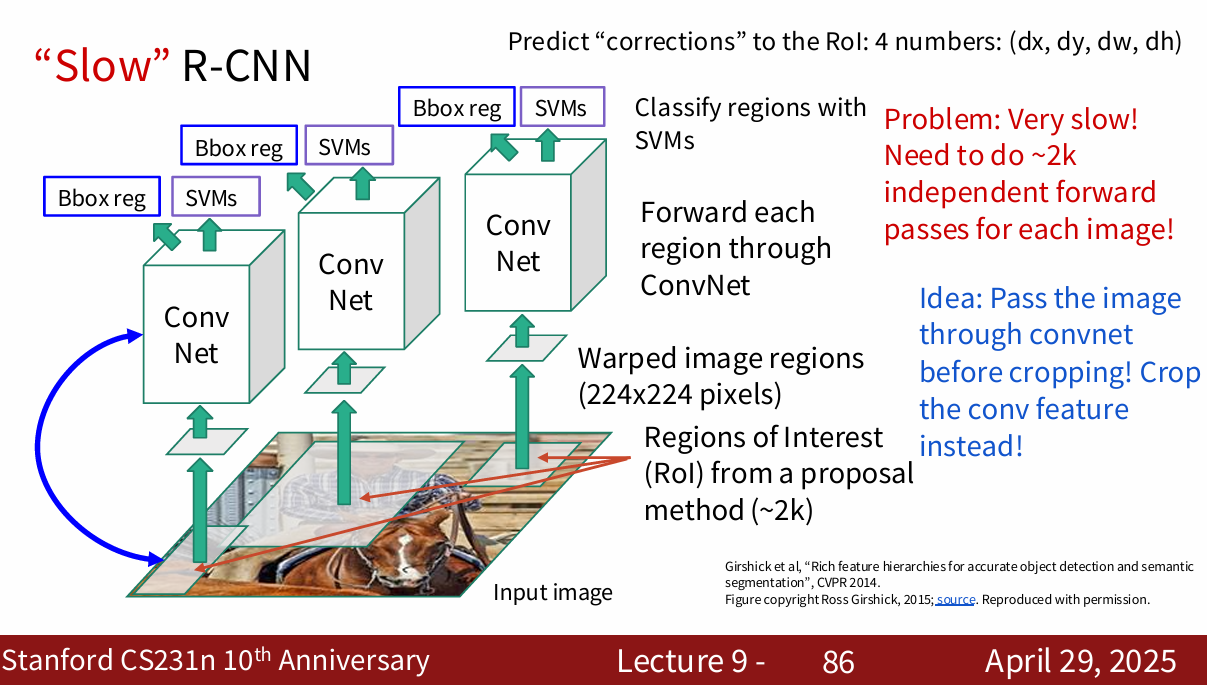
这是个固定算法,人为写好了,不是自学习的
这个算法训练时很慢,占用很大空间,检测时也很慢
fast r-cnn 做了很多优化
用一个很大的cnn,生成整个图像的投影,然后在投影中选出备选区域
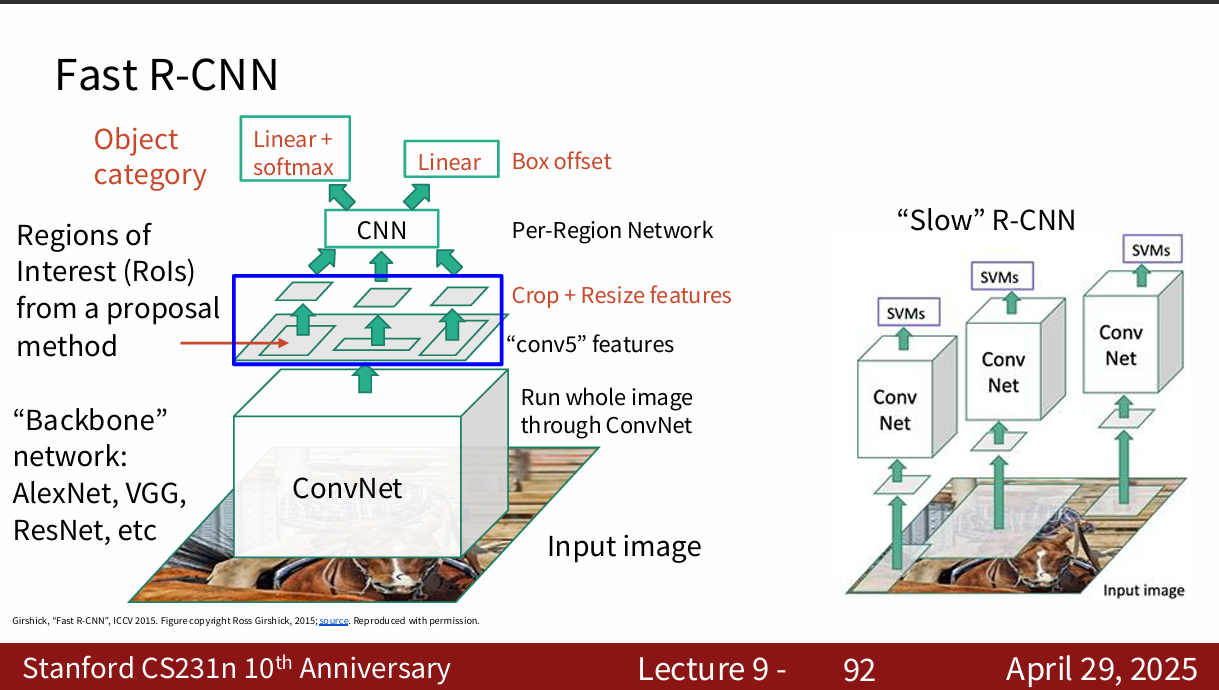
处理过程是共享的,那些复杂计算可以复用。主要是计算备选区域比较慢。 于是有了faster r-cnn,这个东西就更快了
insert region proposal network (rpn) to predict proposals from features
dark magic hyperparameters!
by copilot:
r-cnn
- 借助 Selective Search 给整张图片生成 2000 个左右的 region proposals(候选区域)。
- 把每个 proposal 通过 warp/crop 变成统一尺寸。
- 每个候选区域分别送入 CNN 网络提取特征。
- 用 SVM(支持向量机)对特征做分类(判断有无目标、目标类别)。
- 用回归器做边界框坐标微调(bounding box regression)。
fast r-cnn
- 流程
- 整张图片先经过一次 CNN,得到 feature map(特征图)。
- 利用 region proposals(如 Selective Search 生成)在 feature map 上提取对应的 ROI(候选区域)。
- 所有 ROI 通过 ROI Pooling 层获得固定大小的特征。
- 所有 ROI 特征同时送入全连接层,之后分别输出分类结果和边框回归坐标。
- 优势
- 只需要对整张图片做一次 CNN 前向传播,大幅加快速度。
- 能端到端训练,内存和效率更高。
- Proposal 生成依旧较慢,因为还在用 Selective Search。
faster r-cnn
- 整张图片经过 CNN 得到 feature map。
- 特征图同时进入 Region Proposal Network(RPN),由深度网络自动生成 proposals,代替 Selective Search。
- proposals 在 feature map 上做 ROI Pooling,后续流程同 Fast R-CNN。
- 最终输出目标类别和回归边界框。 改进和优势
- Proposal 生成也用 CNN,可端到端训练,速度提升巨大。
- 检测效果好,速度比前两者快很多。
- 架构已高度一体化,是现代检测算法的重要基石。
Detection without proposals : YOLO
尝试作为回归问题处理
- 将输入图片划分为SxS的网格
每个网格预测若干个(如2个或3个)**边界框(bounding boxes)**及其置信度和类别概率。 - 每个边界框同时预测以下内容:
- 位置(x, y, w, h)
x, y 表示框的中心点相对于格子的坐标,w, h 为宽高相对于整图的比例 - 置信度(confidence)
表示框中有目标的概率以及该框准确地定位了目标 - 各类别的概率(conditional class probabilities)
- 位置(x, y, w, h)
- 模型结构
整张图片仅用一次卷积神经网络(CNN)前向传播就能得到全部检测结果(类别和位置)。 - 后处理
- 对所有边界框进行置信度阈值筛选
- 非极大值抑制(NMS)去除多余重叠框,保留最优预测
Object Detection with Transformers: DETR 坏了,这个transformer真的需要看看
instance segmentation
mask-rcnn
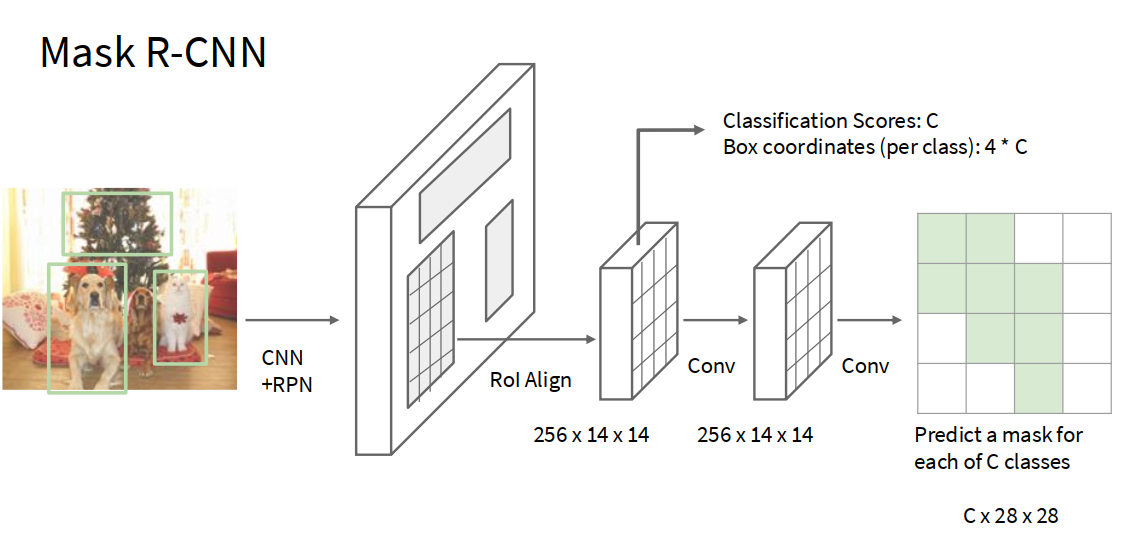
相当于是上面的方法的综合,效果超级好,amazing!
Mask R-CNN 的主要流程
- 主干网络(Backbone)提取特征
- 使用如 ResNet、ResNeXt 或其他 CNN 对整张图片提取特征,生成 feature map。
- 生成候选区域(Region Proposal Network, RPN)
- 和 Faster R-CNN 一样,RPN 网络生成一系列候选目标的候选框(region proposals)。
- ROI Align 与特征提取
- 将 proposals 映射到特征图上后,采用改进版的 ROI Pooling,即 ROI Align,解决了位置量化误差问题,使得像素级分割更准确。
- 目标检测和分割
- 对每个 proposal 分别进行三项预测:
- 类别分类(是哪个类别)
- 边界框回归(精确定位)
- 像素级掩码分割(输出二值掩码,表示该区域属于目标还是背景)
- 对每个 proposal 分别进行三项预测:
主要创新点
- ROI Align 层:解决了传统 ROI Pooling 的对齐误差,使像素掩码预测更加精细和准确。
- 分支结构:在检测分支上多新增了一个独立的掩码分支,专门做分割。
- 端到端多任务训练:同时优化位置检测、目标分类与掩码分割,提升实例分割效果。
semantic segmentation 语义分割
对每个像素分类,不会区分同类型的不同个体 Don’t differentiate instances, only care about pixels
这个在2025课程里里面甚至没讲。欸不对,讲了,但是在很前面。坏了,我怀疑是2017的字幕组弄错顺序了
Semantic Segmentation Idea: Fully Convolutional
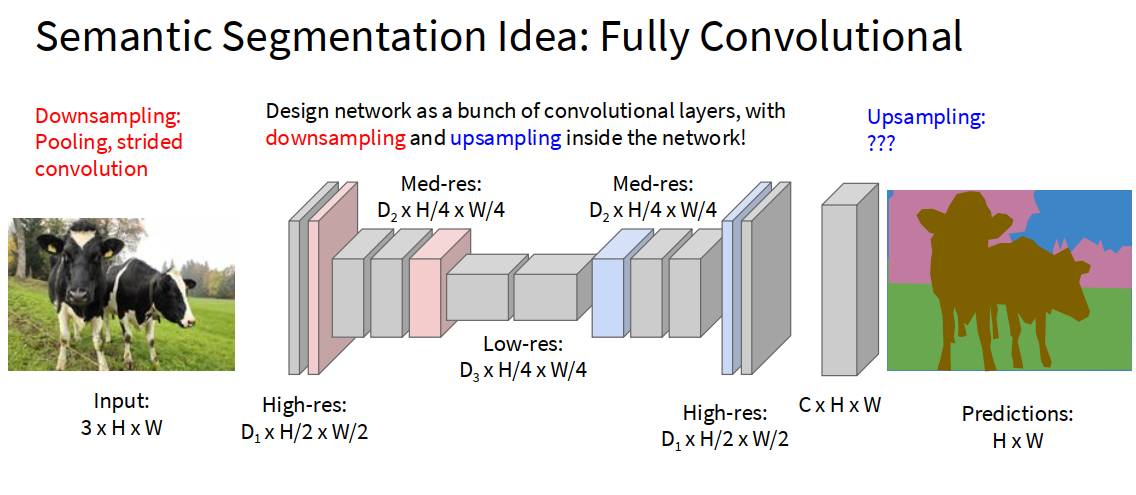
关于 upsampling 需要放大图片,还原图片尺寸
一种方法
Nearest Neighbor 摊开
“Bed of Nails” 填0
或者
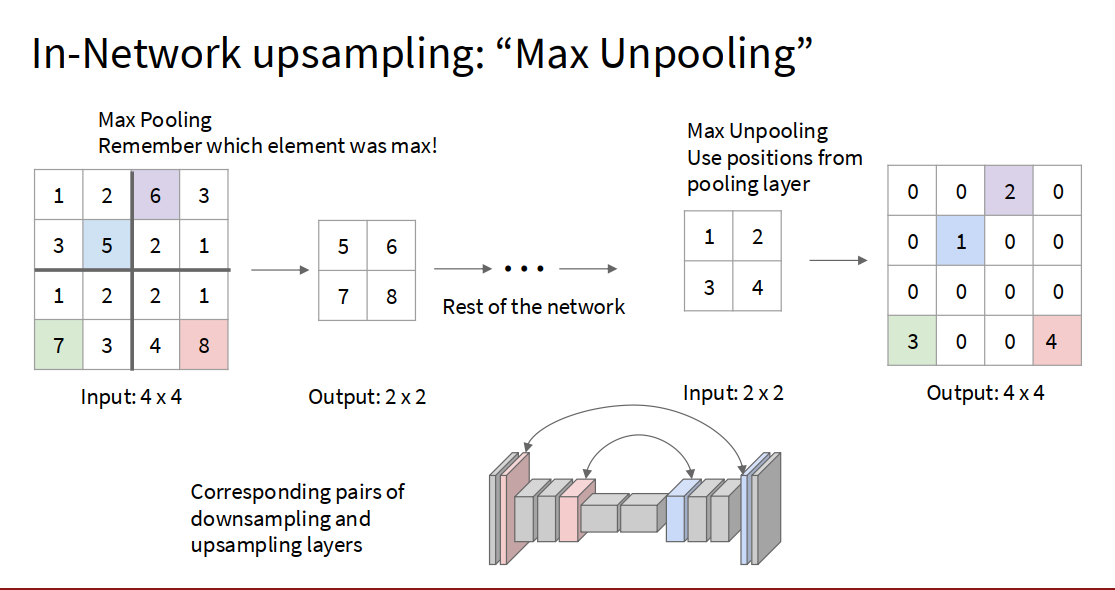
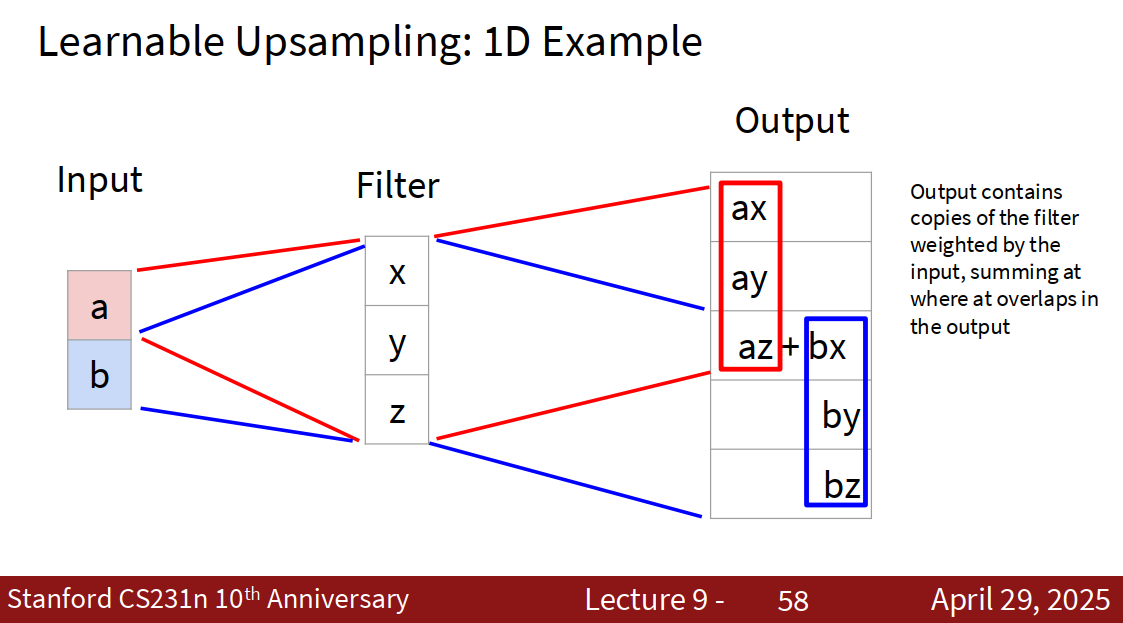
上面的都是固定的,也可以:
Learnable Upsampling: Transposed Convolution
基本定义
- 转置卷积(Transposed Convolution,也称Deconvolution或fractionally-strided convolution),可以通过学习把低分辨率特征图上采样为高分辨率。
- 不同于最近邻或双线性插值等“固定公式”,转置卷积中的参数(卷积核)是可训练的,能根据数据自适应地学习如何有效提升分辨率。 工作原理
- 本质上是对常规卷积操作的“反向”,可以理解为在 feature map 上插“空洞”、再用卷积核进行塌缩与重叠相加。
- 输入尺寸经过转置卷积(结合stride、padding等设置)后变大,实现特征图的放大。
- 计算流程类似“将输入值先稀疏排列后用卷积核滑动相加”。
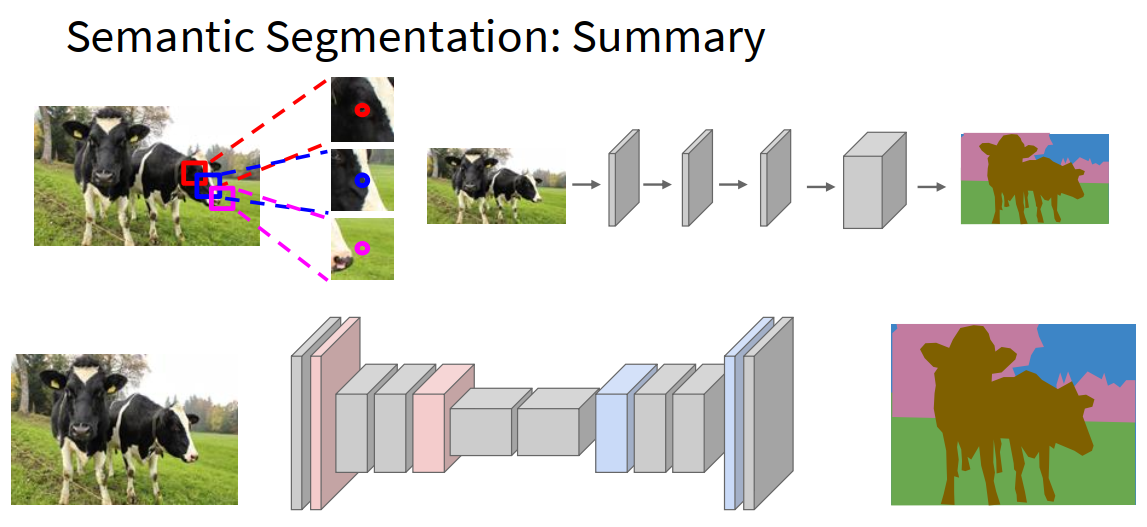
总结
| 任务 | 结果 | 能否区分多个目标 | 是否给出精确像素位置 | 输出 |
|---|---|---|---|---|
| 分类 | 类别 | 否 | 否 | 单一类别标签 |
| 目标检测 | 类别+框 | 能 | 否 | 每个目标的类别和矩形框 |
| 语义分割 | 类别掩码 | 不能区分同类个体 | 能(每像素预测) | 图中每个像素的类别 |
| 实例分割 | 类别+像素掩码 | 能 | 能(每像素预测) | 每个目标的像素级标注&类别 |
p.s. 端到端训练(End-to-End Training) 是指整个机器学习模型从输入到输出,全部环节都在一个统一的系统/网络内通过一次性反向传播(Backpropagation)联合优化,不再需要分阶段(手动设计及训练中间步骤)训练流程。
端到端训练就是把整个任务作为一个统一的大模型,直接优化输入到输出的映射,并且通过一次反向传播训练所有参数,无需分阶段、人为干预中间步骤。
2025-11-16 20点21分 在下院412
2025 lecture8 Attention and Transformers
不行,这个必须得学
- 太重要了
- 2025网课是justin讲的
- 可以参照3b1b的视频
【【公开课·2025春季】李飞飞·斯坦福CS231n计算机视觉课程(全18讲)】 https://www.bilibili.com/video/BV1b1agz5ERC/?p=8&share_source=copy_web&vd_source=278a61d55ec01fcfa1504d3f39f06bbe
【【官方双语】GPT是什么?直观解释Transformer | 深度学习第5章】 https://www.bilibili.com/video/BV13z421U7cs/?share_source=copy_web&vd_source=278a61d55ec01fcfa1504d3f39f06bbe
【【官方双语】直观解释注意力机制,Transformer的核心 | 【深度学习第6章】】 https://www.bilibili.com/video/BV1TZ421j7Ke/?share_source=copy_web&vd_source=278a61d55ec01fcfa1504d3f39f06bbe
2025-11-17 认为看3b1b的不如先看cs231n讲解,先有个大概印象,再建立直观理解
3b1b
关于masking操作
- 本质就是人为将“未来”单元的注意力得分强行变成0(无关),只有自己和前面的词能被参考到。
- 这样每一层Self-Attention实际上实现了“只看左侧(历史)”,保证了自回归式生成的严格信息依赖顺序。
好吧,多层感知机的内容还没有人搬运,既然这样,还是得学cs231n
cs231n
transformer是继承自rnn的
Sequence to Sequence with RNNs and Attention
在编码器,把token编码成向量,这个可以说是最后一个隐藏层,它可以说总结了整个输入序列的信息 然后有解码器,比方说把一种语言对应的向量转化成另一种语言对应的向量
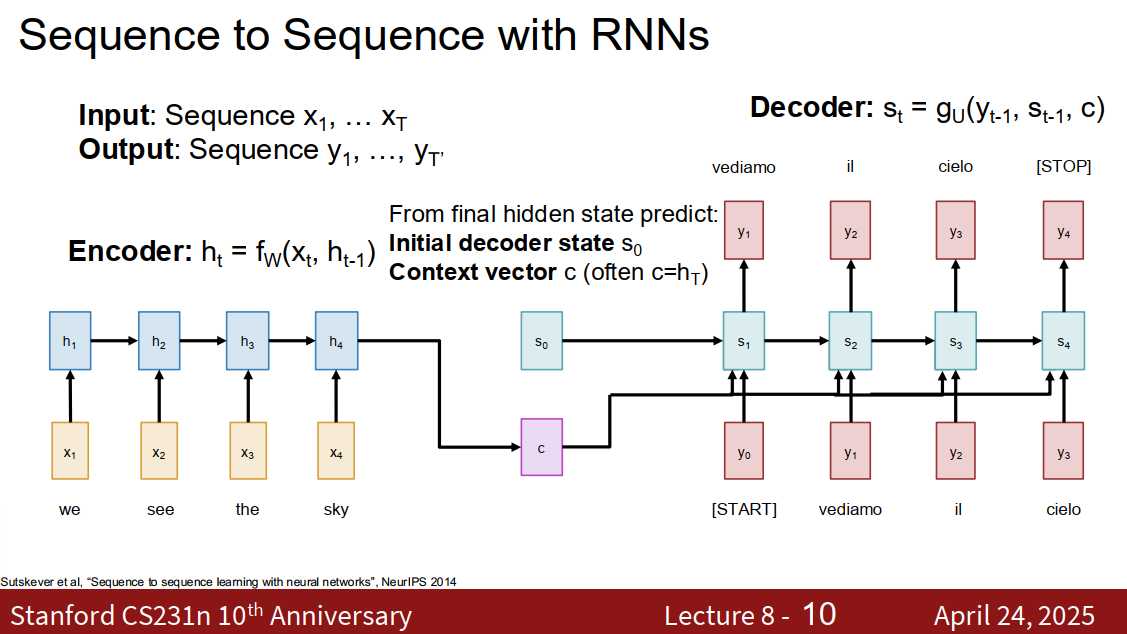
Problem: Input sequence bottlenecks through fixed sized c. What if T=1000?
Solution: Look back at the whole input sequence on each step of the output
为了解决这个瓶颈,每次处理输出序列时,生成输出向量时,都要会看回前的所有输入序列,
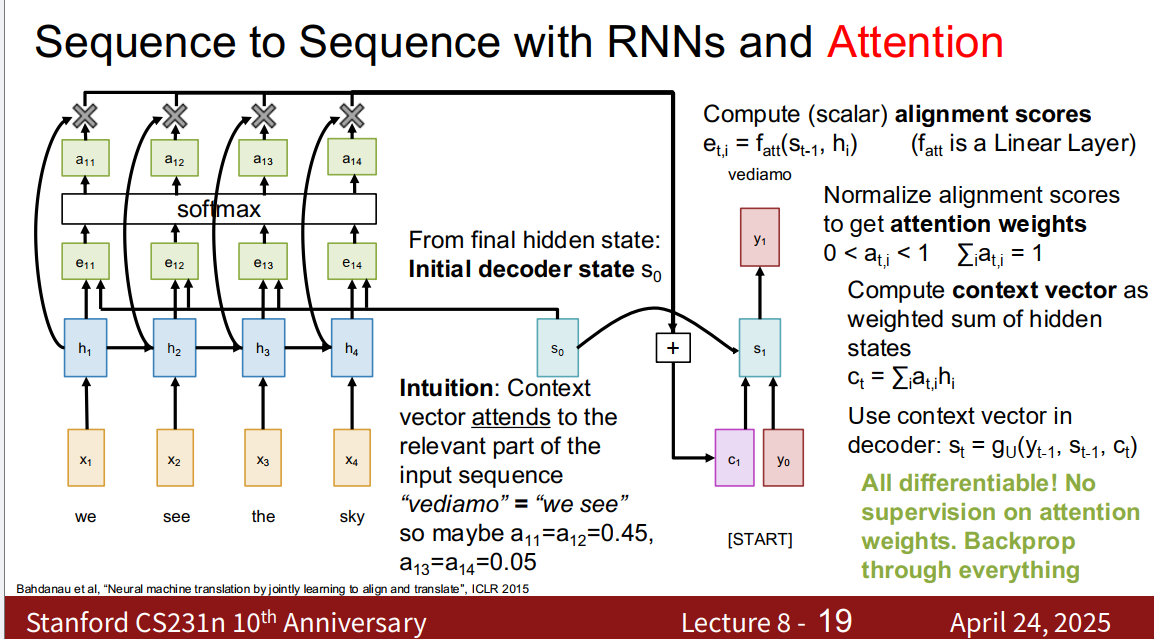
by copilot 这里讲的是,模型中的Attention模块不会单独加监督信号(比如告诉它哪些词应该互相注意),而是通过反向传播和损失函数,把梯度传播到所有参数,包括用来生成attention weights的那部分参数。整个过程可以端到端地学习(不用人为干预Attention)。全部的操作都是可微分的,所以可以直接用梯度下降优化。
由于是每个词对每个词的矩阵,所以是N x N的
关于初始隐藏状态
RNN的每一步计算 但是对于第一个输入 这个就是初始隐藏状态,需要初始化
此外,关于那个计算下一个状态的公式
公式:
各符号含义
- :解码器在时间步 的“隐藏状态” (hidden state),通常是RNN/LSTM/GRU的隐藏状态
- :上一个时间步输出的词或它的嵌入向量(embedding)
- :解码器上一个时间步的隐藏状态
- :第 步的上下文向量(context vector),是编码器输出序列经过Attention机制加权得到的整个输入信息摘要
- :一个神经网络函数,通常是RNN/LSTM/GRU单元,用来组合每个输入信息
中文通俗解释
- 在神经机器翻译等 Sequence-to-Sequence (Seq2Seq) 结构中,解码器生成每个词时,
- 要结合前面已生成的信息(),
- 当前的“记忆”内容(),
- 以及通过Attention机制从编码端抽取的信息总结()
- 这三部分内容会被神经网络综合起来,生成当前步的隐藏状态
- 将被用来预测当前位置应该输出的词
关于那个
- 的由来
在编码器-解码器(Encoder-Decoder结构(比如机器翻译、序列到序列模型)中,上下文向量 起到桥梁作用,让解码器每一步都可以“看到”编码器那边的信息。
而加上 Attention 机制后, 不再是固定的,而是针对于每一个解码时刻 动态计算出来的:
- 编码器会把整个输入(比如一句源语言句子)变成一组向量(记作 )。
- Attention 机制会针对解码器当前时间步 ,计算出一组注意力权重(),表示在当前生成第 个词时,源句每个词的重要程度。
- 上下文向量 就是这些编码器输出加权求和的结果:
- 的作用
- 是解码器每一步生成下一个词的重要输入信息。
- 它相当于每一步都能“带着聚光灯”在输入内容里寻找最关键的信息。
- 在翻译等任务中, 可以聚焦于当前最有用的源语言词,帮助精准生成目标语言的词。
小结
网络自行决定如何利用这个机制
Use a different context vector in each timestep of decoder
- Input sequence not bottlenecked through single vector
- At each timestep of decoder, context vector “looks at” different parts of the input sequence
每次解码时刻都用不同的上下文向量。 在经典的编码器-解码器(Encoder-Decoder)结构里(没有Attention时),
- 整个输入序列的信息被压缩成一个固定的向量(即经典的context vector),这个向量在整个解码过程中都不变;
- 这样会导致“信息瓶颈”:输入太长时,一向量难以表达全部信息。 而有了Attention机制之后
- 每一个解码时刻t都计算一个新的上下文向量ct,它是对输入序列不同部分加权后的结果;
- 这个权重是动态变化的,所以每时刻“看的内容”也不一样。
输入序列信息不再被压缩到一个单一的瓶颈向量里。
- 有Attention时,模型不必“全靠记住”一个context向量;
- 每一次生成输出时,解码器都能直接访问整个输入序列的信息,不会丢失或压缩重要语义。
解码器每一步生成时,都会关注输入里的不同部分。
- 通过Attention机制,不同时间步的context vector会对输入内容分配不同的注意力权重;
- 比如,第i步生成时,可能更关注源句的第2个词;第j步再生成时,可能主要看第5个词。
- 这让输出和输入之间建立了动态且丰富的对应关系。
关于这个上下文向量 传统的 rnn encoder-decoder 关于这里的c,也就是上下文向量,是取编码器最后一步的隐藏状态
在attention机制中,这里的c被换成了,每一步都会重新“看一遍”输入,计算一个属于该步骤的新的context vector,也就是
Query vectors (decoder RNN states) and data vectors (encoder RNN states) get transformed to output vectors (Context states). Each query attends to all data vectors and gives one output vector
what the attention operator is doing: 有一组数据向量,也就是编码器隐藏状态;有一组查询向量,which are the things we’re trying to produce output for;在处理查询向量过程中,我们将回到数据向量,summarise the data vectors in a new custom way for each query vector, and that will produce an output vector, which is the content to be fed into the next tick of the RNN
叽里咕噜说什么呢 by copilot
主要角色
- 数据向量(data vectors):就是“编码器的隐藏状态”,也可以理解为“输入句子的每个词在编码之后形成的向量”,整句每个词各有一个。
- 查询向量(query vectors):就是“解码器当前的隐藏状态”,代表现在模型要产生什么输出(如下一个词)时的“提问”。
- 输出向量(output vectors / context states):经过Attention机制后为每个查询生成的特制“总结”,通常又叫context vector(上下文向量),会作为RNN/Decoder下一步的输入之一。
干了什么 你可以把Attention理解成每个查询向量都有权去整个输入内容里“自助选菜”,做成一份只属于自己的混合菜——这个“菜”就是output vector。步骤如下:
- 解码器每次“准备输出”时,会拿出一个查询向量(比如它目前的隐藏状态);
- 这个查询会和所有的数据向量(编码器输出的每个词的隐藏状态)进行“相关性打分”——哪个输入信息现在对我要生成下一个词更重要?
- 这些相关性打分会用softmax变成一组权重(注意力权重),所有权重加一块等于1。
- 对所有数据向量做加权平均,有的词权重高被关注多,有的权重低被忽略。加权平均的结果就是一个“output vector”,也叫context vector。
- 每一个查询向量都会像这样,取到一个属于自己的output vector,不同的查询会关注输入的不同部分,所以得到不同的“自助菜肴”。
最终作用
- 这个output vector(上下文向量)就专门为当前这个查询(比如正在生成“猫”的时候)定制的信息摘要。
- 它会被送到Decoder/RNN的下一个步骤,辅助它做出更好的输出决策。
Attention Layer
把注意力模块从RNN中抽离出来
放缩后的点积,对于防止梯度消失很关键
Changes
- Use scaled dot product for similarity
- Multiple query vectors
- Separate key and value
完蛋了,那些细节我全部听不懂,完了
48:30 自从开始讲attention层之后,我就什么也不明白了,考虑重新看一遍,在此之前去看看其他直观理解的网课/文章
算了,鉴于MVIG的速通要求,attention+transformer这一块我把3b1b网课看完,建立直观理解就差不多了,然后火速开始速通接下来的课程。
2025-11-23批注: (98 封私信 / 82 条消息) [译] The Illustrated Transformer - 知乎 这个可以看看,有助于理解
lecture 12
【【公开课】最新斯坦福李飞飞cs231n计算机视觉课程【附中文字幕】】 https://www.bilibili.com/video/BV1nJ411z7fe/?p=26&share_source=copy_web&vd_source=278a61d55ec01fcfa1504d3f39f06bbe
可视化和理解 cnn 看看ConvNets里面究竟干了什么,中间层干了什么,在寻找什么,有什么直观理解
第一层:类似于人类视觉早期工作。无论数据集or模型是什么样的,第一层的权重可视化后基本都长那个样子
中间卷积层:可视化后可解释性很差,是一坨不可名状之物,直观而言不知道是什么,因为不是直接连接到图片。不过观察后可以辅助判断激活函数要怎么选择
输入16层(通道)的图片,中间层的卷积核有20个,每一个都是16x7x7的,也就是说每个卷积核都会对所有16通道数据处理并且融合,最后输出是20通道的。(- 一个卷积核,会“全通道遍历”,融合所有通道的信息,得到一张2D特征图。)
为了好的可视化,需要引入一些奇妙小技巧。
最后一层:
- 降维 dimensionality reduction
- 比方说pca算法,更复杂的有t-sne方法,可视化特征的非线性降维算法
- 比方说mnist最后一层,可以看到数据成团
- 提取大量图像,网络运行一遍,记录最后一层对应的4096维特征向量,用降维方法,把4096维特征空间压缩到2维特征空间(x-y),在其中布局网格,观察每个网格位置会出现什么类型的图片
visualizing activations 中间层也可以可视化,看看每一层要寻找的特征在图片里是什么类型的
maximally activating patches 中间的层可能是在找人脸、照相机、某些特定字母等等东西,有点意思
occlusion experiment 遮挡图片的一部分,看看究竟是图像的哪些部分对网络的决策有显著影响。
saliency maps 显著图,比方说可以看到狗的轮廓,发现神经网络在尝试寻找合适的区域
intermediate features via (giuided) backprop 图像哪个区域影响了内部神经元,中间值相对于图像像素的梯度 可能会得到更好的图像,相对于maximally activating patches 由于引导式反向传播,可以知道图像哪一部分影响了神经元打分
visualizing CNN features : Gradient Ascent 用这种方法可以生成能最大激活中间神经元的图像,知道神经元究竟在寻找什么
fooling images / adversarial examples 比方说让一张大象的图被网络识别成考拉熊,虽然看上去没有差异,但是放大后的像素细节差别虽然看上去是一堆随机的东西,却会让模型得出诡异的结果,模型被愚弄了
DeepDream : Amplify existing features
Feature Inversion
Texture Synthesis 临近法 gram matrix neural texture synthesis
挺酷的,可以生成风格类似的图像。
2025-11-21 22点37分 看完了
lecture 13
生成模型 唉,是serena yeung讲 【【公开课】最新斯坦福李飞飞cs231n计算机视觉课程【附中文字幕】】 https://www.bilibili.com/video/BV1nJ411z7fe/?p=28
无监督学习 其中一个子类,生成模型
supervised vs unsupervised learning
监督学习
- data
- x and y
- data and label
- goal
- learn a function to map x → y
- examples
- 分类,回归,检测,等等
无监督学习
- data
- x
- just data, no label
- goal
- 学习数据潜在隐含结构
- 分组,方差,潜在密度等等
- 学习数据潜在隐含结构
- 例子
- clustering
- 降维
- 特征学习
generative models
无监督学习的一类模型 从某种数据分布中生成相似的数据样本
可以解决密度估计问题
PixelRNN PixelCNN
PixelRNN / PixelCNN explicitly parameterizes density function with a neural network, so we can train to maximize likelihood of training data:
- 先决定第 1 个像素,
- 用第 1 个像素的信息决定第 2 个,
- 用前面所有信息决定第 3 个……
- 到第 N 个,每一步其实都是在估计“这个像素在前面都已经定好以后应该是什么(分布)”。
pixel cnn:
generative image pixels starting from corner
for pixelcnn : dependency on previous pixels now modeled using a CNN over context region
training : maxmise likelihood of training images
Training is faster than PixelRNN(can parallelize convolutions since context regionvalues known from training images) Generation must still proceed sequentially⇒ still slow
Pixel RNN/CNN 在做的事就是:
- 让机器学会“根据前面那些像素,来推测下一个像素是什么颜色的概率分布”,
- 然后用这个概率分布随机采样或用最大概率来选。
autoencoders
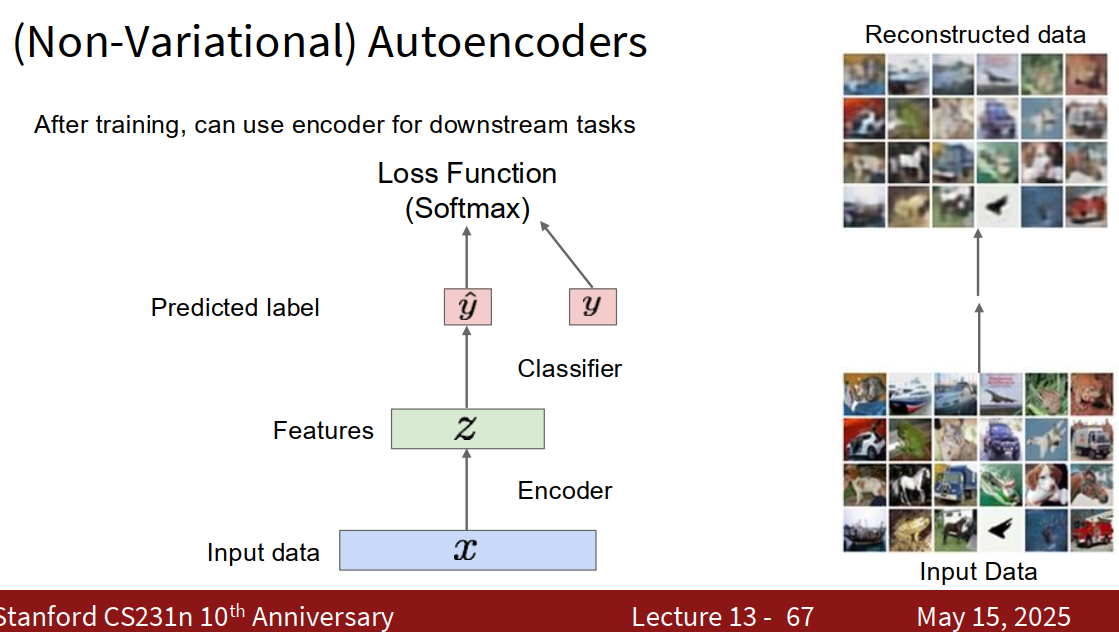
基本流程
- 输入数据(x):比如图像(input data)。
- 编码器(Encoder):将输入高维数据压缩成一个紧凑的特征表示(z)。
- 图中“Features z”就是压缩后的“瓶颈”特征。
- 解码器(Decoder):把 z 再还原成和原来尽量一样的数据(Reconstructed data)。
- “Input Data → Reconstructed data”
- 还原效果不是100%完美,但越像越好。
训练目标
- 用损失函数(Loss Function),度量重建的图片(Reconstructed data)和原始图片(Input Data)差距,让网络学会尽量保留关键信息。
- 同时,也可以把编码器学出来的“特征 z”拿来做下游任务(比如分类),图里体现为“Classifier”模块和 Softmax 损失。
下游任务
- 训练完后,可以直接用“Encoder”提取得到的数据特征(z)做分类、聚类等下游机器学习任务。
- 图中心的“Features z”向上连着分类器,产出预测(Predicted label)。
Autoencoder 就是通过“压缩-还原”过程,让数据自己教自己学出“精华特征”,一方面可以还原数据,另一方面提取出来的 z 特征也能直接用于其他任务。
Autoencoders can reconstructdata, and can learn features to initialize a supervised model Features capture factors of variation in training data. Can we generate new images from an autoencoder?
于是就有了 Variational Autoencoders
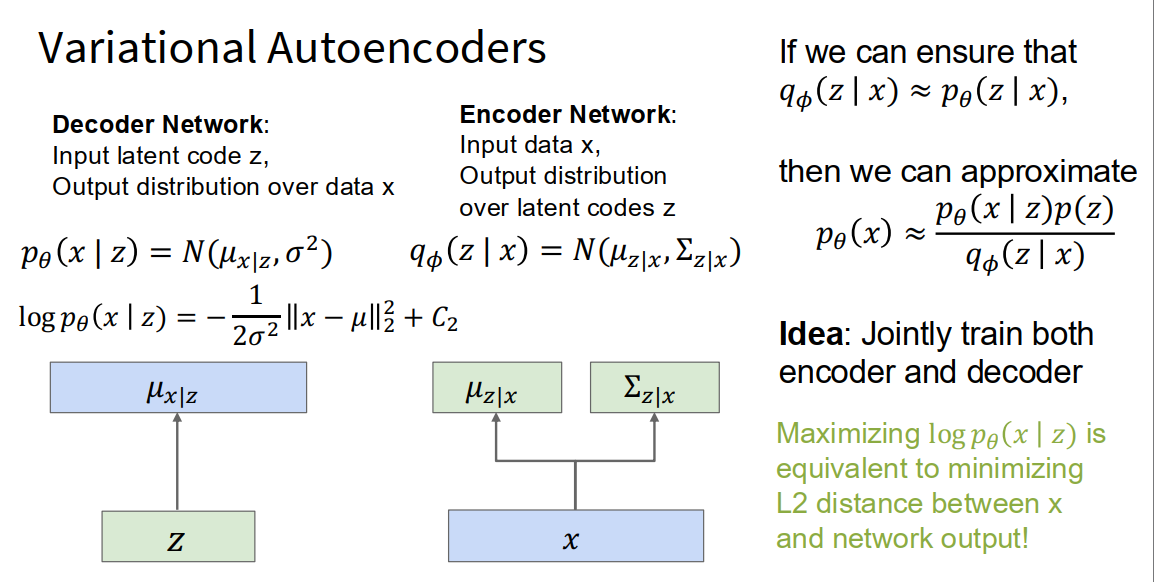
Variational Autoencoders (VAEs)
原理
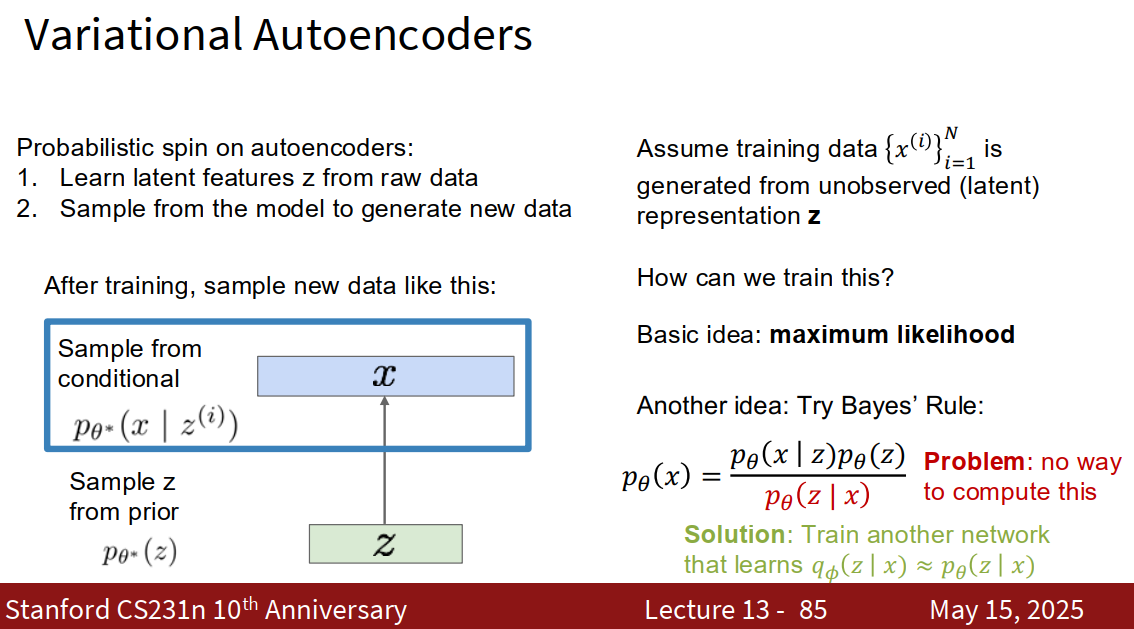
基本流程
- 训练时:假定训练数据是通过某种“潜在变量 z”生成出来的,VAE目标是找到这种映射关系。
- 生成时(如图左下蓝框):
- 先从一个已知的概率分布(比如高斯分布 p(z))里随机采样一个 z。
- 再用“解码器”根据 z,生成出新的数据 x,即从 p(x|z) 采样。
数学原理
-
训练思路本质上是“最大似然估计”(maximum likelihood),让生成的数据尽可能像真实数据。
-
也可以用贝叶斯法则推导:
但这个积分难以直接算(图右下红字 Problem),因为 p(z|x) 很难求。
solution
- VAE 的核心创新:引入第二个神经网络,去近似 (即推断 z 的分布),用 近似(Solution部分)。
- 使得训练和采样都变得高效,实现“既能学特征,又能自由生成”。
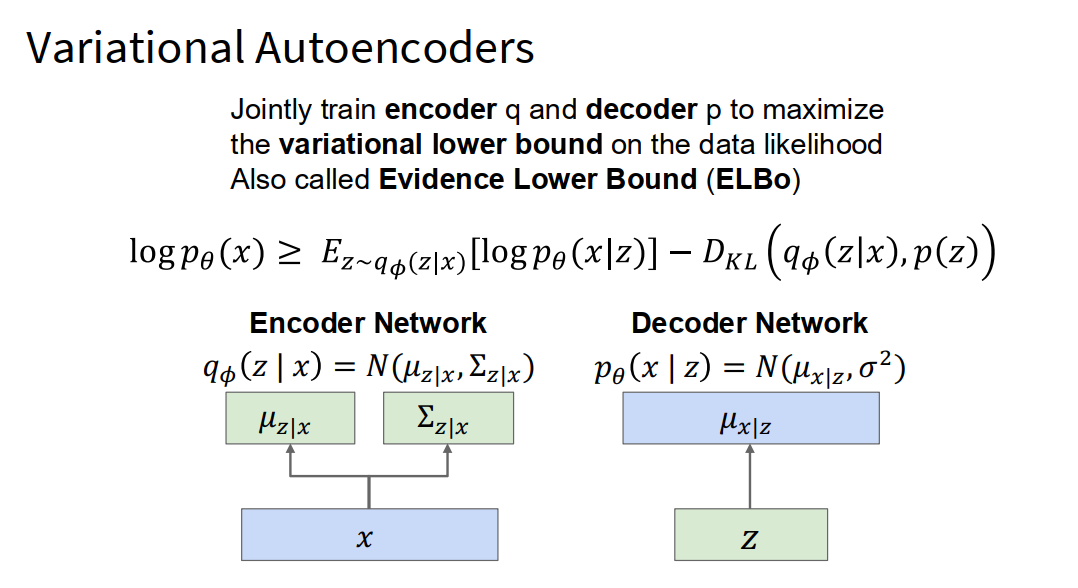
training

The loss terms fight against each other!
Reconstruction loss(左边一坨) wants and to be unique for each , so decoder can deterministically reconstruct
Prior loss(右边一坨) wants and so encoder output is always a unit Gaussian
- Reconstruction loss(重建损失,左边一坨)
- 中文叫“重建损失”或者“复原误差”。
- 含义:让网络把压缩之后的数据(z),还原得尽量和原来的x一样。
- 理解:
就像“你背出来的内容越详细,回忆出来的原图越像原来”。 - 数学上,这部分鼓励每张图都有属于自己的、独特的z,而且z的方差(Σz|x)越小越好,最好每次都能还原为同一张图(deterministic)。
- Prior loss(先验损失,右边一坨KL)
- 中文叫“先验约束”或者“分布正则化”。
- DKL 是“KL散度”,简化来说就是让网络学到的z分布不要乱跑,要像一个标准正态高斯(0均值、1方差)。
- 理解:
就像“要求你不管什么图片,你记住的内容类型都要接近于大部分人的记忆方式,不能每个人都太特殊”。 - 数学上,这部分想让每个编码出来的z都分布在0附近,方差=1(标准高斯球)。
这是VAE的核心损失函数,左边让模型尽量还原数据,右边让隐变量z分布接近标准正态,两者一起保证“生成的z既有代表性又很泛化”,最终既能准确还原也能生成新东西!
Generative Models So Far
Autoregressive Models directly maximize likelihood of training data:
Variational Autoencoders introduce a latent ( z ), and maximize a lower bound:
GANs
Generative Adversarial Networks
Generative Adversarial Networks give up on modeling p(x), but allow us to draw samples from p(x)
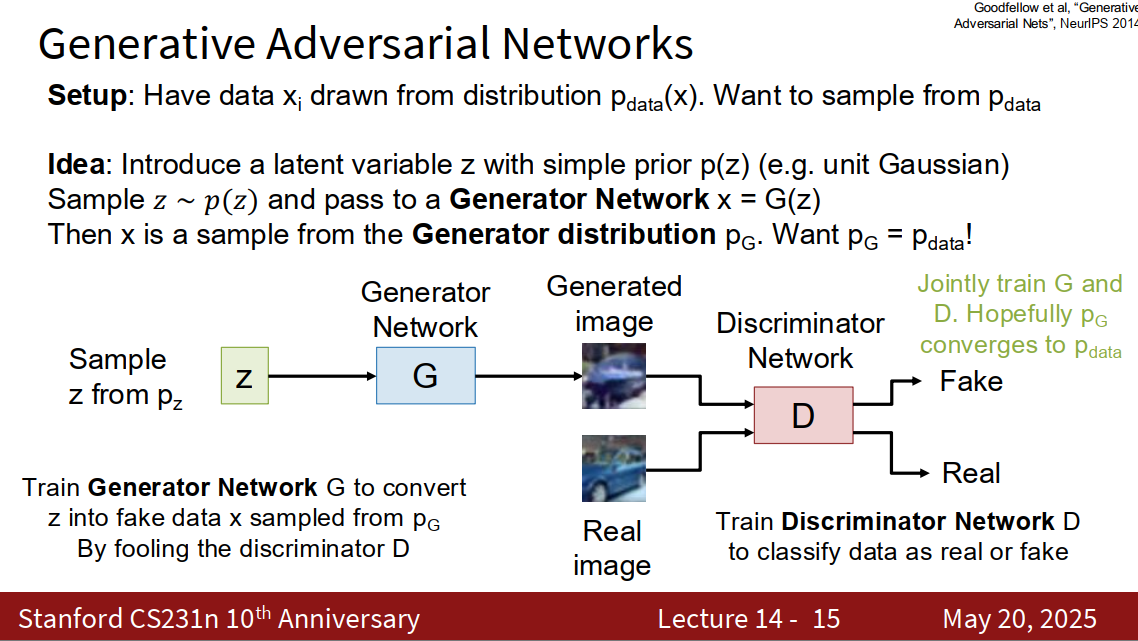
训练可以生成骗过discriminator network的图片的模型
Jointly train generator G and discriminator D with a minimax game

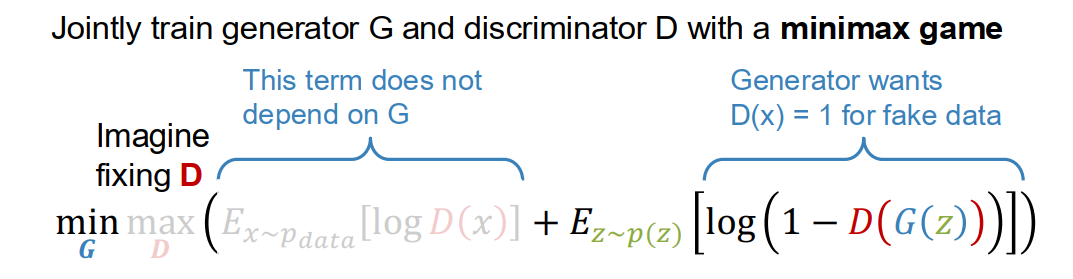

- 没有“总损失值”可以直接看,也没有像其他模型那样越训练损失越小的曲线。
- 训练过程是 G 和 D 轮流互相优化,类似轮流下棋
D要梯度上升,G要梯度下降
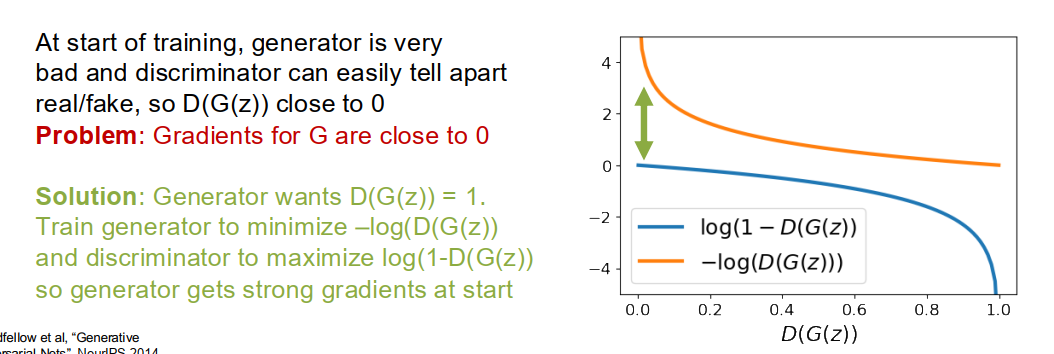
问题
- 一开始,生成器G画得很烂,判别器D很容易识别“这是假的”。
- 此时 D(G(z)) ≈ 0,意思是“判别器认为生成器画的几乎全是假的”。
- 问题在于:此时G的梯度非常小(接近0),优化G的过程学得非常慢(几乎不更新)。 原因
- 如果用原始GAN损失:
- G尝试最小化 log(1-D(G(z)))。
- 当 D(G(z)) ≈ 0 时,log(1-0) = log(1) = 0,梯度变得极小,G难以进步。 解决办法
- 改变生成器的目标,让它最大化判别器认为“生成图片是真的”(即 D(G(z)) 接近1)。
- 换句话说:
- 生成器用的损失变成:-log(D(G(z)))。
- 判别器用的损失还是:log(1-D(G(z)))。
- 这样在生成器很弱、D(G(z))接近0时,-log(D(G(z))) 这个损失给G传递的梯度会很大,有助于G快速学习。
Diffusion Models
这个是2025 cs231n引入的东西
Warning: Terminology and notation in this area is a mess!
There are many different mathematical formalisms; tons of variance in terminology and notation between papers.
We’ll just cover the basics of a modern “clean” implementation (Rectified Flow)
简介
- 本质是一种能“从噪声中生成高质量图片”的生成模型。
- 灵感像“倒带录像”:
- 正向过程:把一张清楚图片慢慢加噪声直到变成杂音。
- 反向过程:训练模型学着怎样从纯噪声一步步反推出清晰图片。
- 用数学说就是:通过反向扩散过程(reverse diffusion process) 采样出新图像。 极简流程
- 正向流程(加噪)
拿一张真实图片,每次加一点点高斯噪声,连加N次,最后变成完全噪音。 - 反向流程(去噪)
训练一个“去噪模型”:给它一张带噪的图片,它要学会输出“减去这一层噪声应该变成啥”。- 反复这样(逐步),一步步去除噪声,最后还原出清晰的图片。
- 生成新图片
- 先从一个纯噪音(高斯噪声)开始
- 让模型一步步帮你“去噪”,直到变清楚,这样就能凭空生成新图片!
Recap
Generative Models
- PixelRNN and PixelCNN
- Explicit density model, optimizes exact likelihood, good samples. But inefficient sequential generation.
- Variational Autoencoders (VAE)
- Optimize variational lower bound on likelihood. Useful latent representation, inference queries. But current sample quality not the best.
- Generative Adversarial Networks (GANs)
- Game-theoretic approach, best samples! But can be tricky and unstable to train, no inference queries.
有机会再学吧! 2025-11-22 17点08分
lecture 14
Reinforcement learning
深度增强学习,唉还是serena yeung
看了看,这一课包含在2025课程的Lecture 17: Robot Learning里面
- Deep Reinforcement Learning
- Model Learning
- Robotic Manipulation
goal : learn how to take actions in order to maximise reward
Reinforcement Learning
一些例子
Markov Decision Process
马尔可夫决策链
by copilot 马尔可夫决策链(Markov Decision Process,简称MDP)是一种用于建模具有随机性和决策因素的动态系统的数学框架。其核心思想是在一个状态空间中,智能体通过采取动作与环境交互,环境根据当前状态和动作以一定概率转移到下一个状态,同时给予相应的奖励。MDP广泛应用于强化学习和自动控制等领域。
MDP的基本要素包含:
- 状态集(States, S):所有可能的环境状态。
- 动作集(Actions, A):在每个状态下可进行的所有动作。
- 状态转移概率(Transition Probability, P):当前状态执行动作后转移到下一个状态的概率。
- 奖励函数(Reward, R):每一次状态转移后得到的即时奖励。
- (可选)折扣因子(Discount Factor, γ):度量未来奖励的重要程度。
MDP有一个重要的特性——马尔可夫性,即“无记忆性”:下一个状态和奖励只依赖于当前状态和动作,与过去的状态和动作序列无关。
- 目标是通过选择最优动作序列,获得最大累计奖励
The optimal policy We want to find optimal policy that maximizes the sum of rewards.
Q*(s, a) 满足最优贝尔曼方程:
- 先在状态 s 采取动作 a,获得奖励 r
- 环境转移到 s’(这个转移可能有概率分布,所以要算期望)
- 在新状态 s’,选一个最优动作 a’,最大化 Q*(s’, a’) 作为后续最大奖励
- γ 为折扣因子
- 指对所有可能到达的新状态 s’ 求期望
贝尔曼方程
- Q*(s, a) 定义了最优情况下,每一步做什么最值钱
- 贝尔曼方程把它拆成“当前奖励 + 未来最优奖励”
- 所有的强化学习算法(像 Q-learning、DQN)都是围绕这个方程来学习/求解的
Q-learning
Solving for the optimal policy: Q-learning
Remember: want to find a Q-function that satisfies the Bellman Equation:
最优 Q 值等于「这步即时奖励 + 未来所有最优 Q 值的最大值的加权和(加上折扣 γ)」。
训练过程: Q-learning 通过不断优化 Q 函数,使它越来越满足贝尔曼方程。
Forward Pass
Loss function:
这里
- θi:表示当前 Q 函数的参数(如果用神经网络拟合 Q 值,就是网络参数)
- 损失函数其实就是「目标 Q 值」和「当前 Q 值」的平方差
where
也就是根据贝尔曼方程,用上一次更新的参数算出来的“理想答案”。
Backward Pass
Gradient update (with respect to Q-function parameters ):
- 这一步,就是常见的「用损失反向传播+梯度下降」来优化 Q 函数的参数
总结
- Q-learning 就是反复让 Q 函数去逼近贝尔曼方程的解
- 训练时:会用当前 Q 函数和目标 Q 值算损失,然后用梯度下降一步步让 Q 函数变准
Q-network architecture
Q-network 就是用神经网络来学会给“状态+动作”打分,这个神经网络的结构(输入输出长啥样、里面有几层)就叫 Q-network architecture。
结构
- 输入层:输入一般是“状态s”(比如当前棋盘、当前游戏界面),有时候还会加上“动作a”编码。
- 隐藏层:几层神经元,负责学习复杂映射关系(比如一开始乱猜,训练多了就变聪明能预测奖励)。
- 输出层:输出所有动作的 Q 值(比如在某个状态下,往左/右/跳/打怪分别的得分是多少)。
常见的就是:输入状态,输出每个动作的值 比如玩游戏,输入是屏幕分辨率的像素,输出是:按上、下、左、右、发射,每个动作的评分。
experience replay
Learning from batches of consecutive samples is problematic:
- Samples are correlated ⇒ inefficient learning
- Current Q-network parameters determines next training samples (e.g. if maximizing action is to move left, training samples will be dominated by samples from left-hand size) ⇒ can lead to bad feedback loops
Address these problems using experience replay
- Continually update a replay memory table of transitions (, , , ) as game (experience) episodes are played
- Train Q-network on random minibatches of transitions from the replay memory, instead of consecutive samples
deep q-learning with experience replay DQN
putting it together
1. 初始化部分
- Replay memory D:相当于准备一个“大记事本”,用来记录游戏过程中的“经历”。
- Q网络:随机初始化,“还不会玩”。
2. 每轮游戏(每个episode)
- 每次玩一局游戏(比如玩一次贪吃蛇),记录游戏过程。
游戏每一步(循环 t = 1, 2, 3, …)
- 选动作(探索或利用)
- 有一定概率随机出拳(探索新招式,让AI有机会尝试不同操作)。
- 否则,让AI用目前学到的Q网络来判断哪个动作分高,选分最高的(利用已有知识)。
- 执行动作,观察新状态和奖励
- 做出动作,看看环境(比如游戏界面)有什么变化,得了多少分。
- 记录这一步到“大记事本”D里
- 把“这一步的状态、动作、奖励、下一状态”都存下来。
- 每隔一段时间,从记事本里随机挑出一批经历来训练(经验回放)
- 不用全部用最近的经验,而是随机抽取,防止AI“死记硬背”。
- 算目标值 y_j
- 如果已经输了,目标值就是这次得到的奖励。
- 如果没死,还没结束,目标值加上后面最优Q值(贝尔曼方程)。
- 用梯度下降让Q网络变得更准(训练网络)
- 用这批“回放”的经历,调整Q网络,把自己预测的Q值往真实目标值靠拢。
3. 不断重复,不断进步
- 随着玩得多了、训练多了,神经网络就能越来越准,变成超级玩家!
policy gradients
q-learning的问题
- Q-learning 要学的是 Q 函数(Q-value):它要知道“每一个状态 + 每一个动作”的“价值”。
- 问题在于,如果状态和动作太多(比如机器人手指很多,每个关节都可能弯曲角度不一样),那每种可能都要算一个 Q 值,会超级复杂,难以穷举学完。 但是
- 其实有时候,不需要知道每个小细节的“分数”,只要学会“怎么做才容易成功”就行了。
- 比如策略直接可以是“遇到东西就闭手”,这比算所有动作的Q值简单多了。 于是
- 改变思路,直接学“做事的方法(策略)”本身,而不是每一对“情况-动作”的分数。
- 策略梯度方法的目标就是:直接找到最好的“行动准则”,而不是先算一堆Q分数再挑。
总结
Q-learning像“给每一种情况打分”,太复杂时就难学。
策略梯度是“直接学做事的方法”,不要每种都算分,反而效率更高。
REINFORCE algorithm
Mathematically, we can write:
Where is the reward of a trajectory
- :代表策略的“期望总奖励”——也就是我们努力要最大的那个东西(目标函数)。
- :是我们现在这套“做事方法”里的参数(假设你用神经网络表示策略,这就是网络的参数)。
- :表示一次“完整的经历”(一个“轨迹”),比如一次游戏经历,包含了一系列的“状态、动作、奖励”组合。
- :表示这一次经历最终得到的累积奖励。
- :表示在现在这套策略(参数为)下,经历轨迹出现的概率。
reinforce的目的是:直接调策略的参数(θ),让最终奖励平均值最大。
- 这个和Q-learning不同,Q-learning是让Q函数拟合贝尔曼方程。
- REINFORCE是直接“看结果好不好,通过结果来调整下一次行动方法”,完全不需要中间Q值。 REINFORCE
- 是一种用“梯度下降”直接优化“拿到更多奖励的做事方法(策略)”的算法。
- 不需要知道每一种小动作的Q值,而是看整条经历、整体结果。
- 是策略梯度家族最直接的数学表达方式。


third idea : baseline

- 在梯度公式中,把每次获得的总奖励减去一个“基线”值,基线一般是某种“平均回报”。
- 这样做可以让梯度估计的方差进一步降低,让学习过程更加平滑、稳定。
actor-critic algorithm
- Actor 决定走哪一步——它就是我们的策略。
- Critic 对每步的选择给出反馈(比如说“你这个选择比平均水平好/差多少”)。
- Actor根据Critic的反馈调整自己的策略,让未来选动作越来越好。
- Actor用梯度上升法调整策略参数,目标是让“好事做得更多”;
- Critic用时序差分(Temporal Difference, TD)方法估计当前行为的好坏,经常用优势(advantage):A=r+γV(s′)−V(s) 来反馈Actor的每一次选择。
Recurrent Attention Model, RAM
- 不看全图,只看“局部细节(glimpse)”
模仿人眼/人类注意力机制,像“眼睛注视点”那样,**每一步只挑一个小区域”看。 - 步骤如下:
- 系统每一步挑一个点,看一个小区域(glimpse)。
- 反复多步,每一步选择下一个“要看的区域”。
- 看完几步后,综合所有“看过的区域”来判断图片属于哪一类。
- 优点
- 不用每次全图扫描,省计算资源(加快速度)。
- 能学会忽略无关干扰区域,只关注重要部分。
强化学习里的对应元素
- 状态(State):目前为止已经看过的所有glimpse(局部区域的集合)。
- 动作(Action):下一个要看的地方(即glimpse的中心点坐标x, y)。
- 奖励(Reward):如果最后分类对了,奖励1,否则0。
summary
- Policy gradients: very general but suffer from high variance so requires a lot of samples. Challenge: sample-efficiency
- Q-learning: does not always work but when it works, usually more sample-efficient. Challenge: exploration
- Guarantees:
- Policy Gradients: Converges to a local minima of J(θ), often good enough!
- Q-learning: Zero guarantees since you are approximating Bellman equation with a complicated function approximator
| Q-learning | Policy Gradient | |
|---|---|---|
| 学的是? | 每个(状态,动作)的Q值 | 直接学一个参数化策略 |
| 决策方式 | 查Q表/网络,选Q值最大 | 策略网络输出概率,按概率选 |
| 优化目标 | 逼近贝尔曼方程 | 最大化期望总回报 J(θ) |
| 需不需要显式遍历所有动作 | 需要 | 不需要 |
| 适合问题 | 动作空间不太大、易于枚举 | 动作空间大、连续控制更合适 |
- Q-learning像是在“明确打分”各种做法,最后按分数挑最优。
- 策略梯度就是跟着“直觉做事”,不断调整直觉让结果越来越好——这种直觉(参数)就是策略本身。
16点06分 2025-11-23
lecture 15
深度学习高效的方法和硬件(Efficient Methods and Hardware for Deep Learning)
大模型训练有很多挑战
优化方法:有很多
高效训练
22点38分 2025-11-23 这个好像更类似于讲座,介绍一些前沿的东西,听着玩
lecture 16
对抗性样本和对抗性训练(Adversarial Examples and Adversarial Training)
不是正儿八经的东西
可以看看lecture12里面的 fooling images / adversarial examples
23点18分 2025-11-23 这个人讲完之后大伙给他鼓掌了,听起来他讲得也专业很多。
2025-11-24 接下来认为要干的
- 先把transformer学了!
- 然后2025年课程看情况接着学
【没事写写日记】菲比?菲比啾比! - 水源广场 / 谈笑风生 - 水源社区 Flow Matching and Diffusion Models
diffusion 过一遍这个就够了
可以作为参考